6 Manipulación de datos
En la práctica del análisis estadístico es habitual trabajar con conjuntos de datos que no se encuentran en el formato adecuado: archivos de datos —como planillas de Excel— con nombres de variables poco claros, filas innecesarias, valores faltantes o variables que requieren ser transformadas.
En este contexto, la preparación de los datos no es una tarea secundaria, sino una etapa fundamental del proceso de análisis. Antes de avanzar hacia la visualización o el modelado, resulta imprescindible ordenar, limpiar y transformar los datos de manera sistemática. Este proceso, conocido como data wrangling, forma parte de un flujo de trabajo iterativo en el que los datos se refinan progresivamente.
El enfoque del tidyverse se basa en el concepto de datos “ordenados” (tidy data), donde cada variable se organiza en una columna, cada observación en una fila y cada unidad de análisis en una tabla. A partir de esta estructura, es posible aplicar herramientas consistentes y expresivas para manipular datos.
En este capítulo aprenderemos a utilizar funciones clave del tidyverse para seleccionar variables, filtrar observaciones, crear nuevas variables, reorganizar datos y resumir información, con el objetivo de construir flujos de trabajo claros, reproducibles y eficientes.
6.1 Carga del tidyverse
Como se mencionó en capítulos anteriores, antes de comenzar es necesario contar con los paquetes que utilizaremos a lo largo del análisis. Si es la primera vez que se trabaja con el tidyverse, el paquete debe instalarse:
Una vez instalado, se carga en la sesión de R con la función library():
6.2 La base de datos
Para los ejemplos de este capítulo utilizaremos el dataset PlantGrowth, disponible en R base. Este conjunto de datos contiene los resultados de un experimento donde se comparó el rendimiento, medido como peso seco de plantas, bajo una condición control (ctrl) y dos tratamientos diferentes (trt1 y trt2).
La estructura de estos datos es muy similar a la de un ensayo experimental típico del ámbito de las Ciencias Agrarias, lo que permitirá ilustrar de manera clara las herramientas de manipulación de datos.
Se puede consultar la documentación del dataset de la siguiente manera:
Para visualizar las primeras filas del dataset utilizaremos la función head():
## weight group
## 1 4.17 ctrl
## 2 5.58 ctrl
## 3 5.18 ctrl
## 4 6.11 ctrl
## 5 4.50 ctrl
## 6 4.61 ctrlPara explorar su estructura de manera más detallada utilizamos glimpse(). Esta función del tidyverse nos permite verificar rápidamente si R está interpretando correctamente nuestras variables: por ejemplo, si el peso es una variable numérica (<dbl>) y si el grupo es una variable categórica (<chr>) o factor (<fct>).
## Rows: 30
## Columns: 2
## $ weight <dbl> 4.17, 5.58, 5.18, 6.11, 4.50, 4.61, 5.17, 4.53, 5.33, 5.14, 4.8…
## $ group <fct> ctrl, ctrl, ctrl, ctrl, ctrl, ctrl, ctrl, ctrl, ctrl, ctrl, trt…6.3 Ordenar y transformar datos
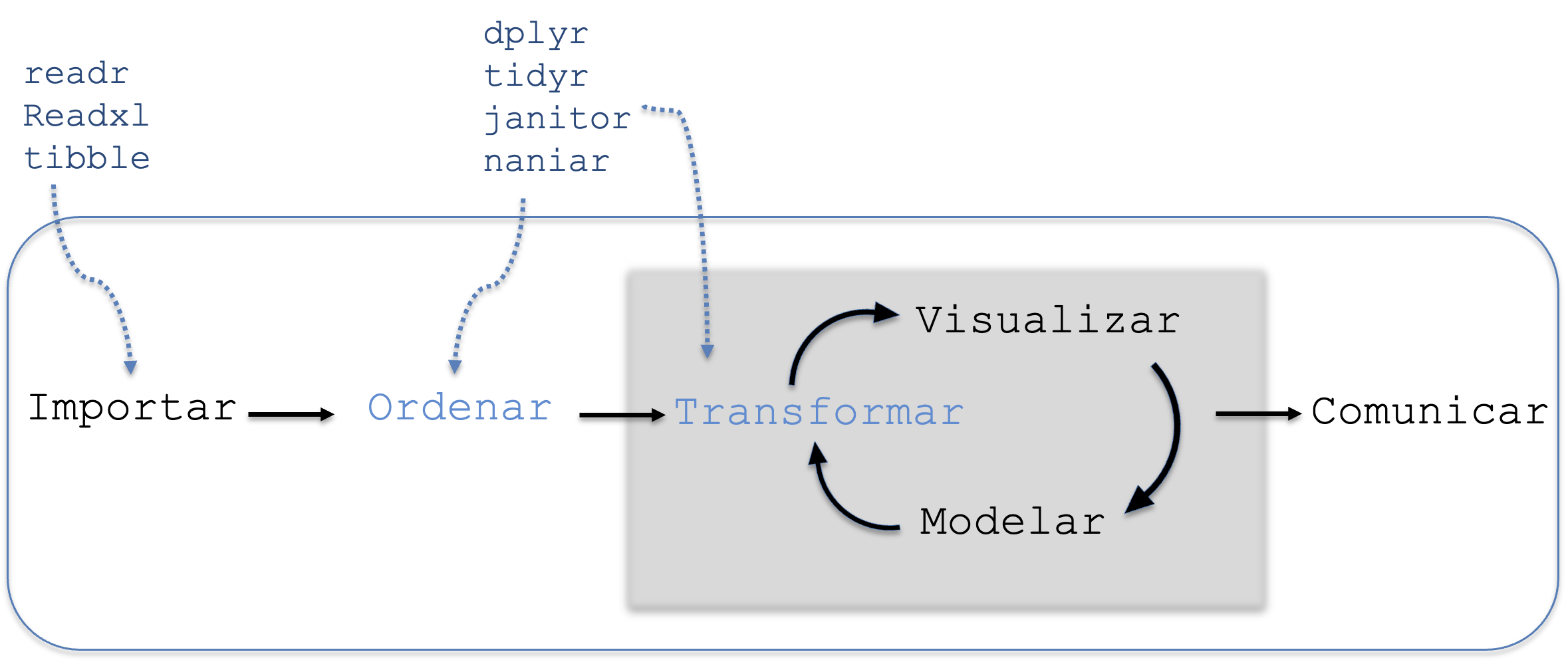
Figura 6.1: Etapa de ordenamiento y transformación de datos.
Tal como se ilustra en el esquema de la Figura 6.1, esta etapa del flujo de trabajo se enfoca en preparar los datos para su análisis. Como puede observarse en la imagen, existen varios paquetes disponibles para esta etapa, como dplyr, tidyr, janitor y naniar.
En este capítulo trabajaremos con dplyr, que forma parte del tidyverse y es el paquete más utilizado para la manipulación de datos en R.
Al final del capítulo se presenta una breve descripción de otros paquetes complementarios para quienes deseen profundizar en el proceso de preparación de datos.
6.4 El paquete dplyr
![]()
dplyr es uno de los paquetes que integran el tidyverse y proporciona una gramática coherente para la manipulación de datos. Su enfoque se basa en un conjunto reducido de funciones, denominadas verbos, que permiten resolver las operaciones más frecuentes en el procesamiento de datos.
6.5 Funcionamiento general de dplyr
La sintaxis y el funcionamiento de los verbos de dplyr comparten una estructura lógica común que facilita su aprendizaje y aplicación:
El primer argumento es siempre un data frame o tibble. Esto permite identificar sobre qué objeto se realizarán las operaciones.
Referencia directa a variables. Los argumentos posteriores describen las acciones a realizar sobre las columnas. Se puede hacer referencia a ellas directamente por su nombre, sin necesidad de usar comillas o el operador
$, lo que incrementa significativamente la legibilidad del código.El resultado es un nuevo data frame. Al devolver siempre un objeto con la misma estructura (un tibble), se facilita el encadenamiento de múltiples transformaciones de manera consecutiva.
6.6 Los verbos de dplyr
Para organizar el trabajo, podemos clasificar los verbos principales en tres categorías según el nivel en el que operan dentro del conjunto de datos:
Operaciones con filas:
filter(): permite seleccionar un subconjunto de filas que cumplen con criterios lógicos específicos.arrange(): se utiliza para reordenar las filas en función de los valores de una o más variables, ya sea de forma ascendente o descendente.
Operaciones con columnas:
select(): permite seleccionar un subconjunto de columnas de interés en una base de datos.rename(): se emplea para modificar los nombres de las columnas, facilitando su interpretación.mutate(): crea nuevas variables a partir de cálculos o transformaciones de las existentes.
Operaciones con grupos de filas:
summarise(): facilita el cálculo de medidas de resumen.group_by(): agrupa las observaciones según una o más variables categóricas (factores), estableciendo una estructura interna para análisis segmentados.
Además de estos verbos, dplyr incluye una vasta gama de funciones adicionales que extienden sus capacidades. Estas propiedades facilitan la construcción de secuencias de operaciones simples que al combinarse, permiten desarrollar flujos de trabajo claros, reproducibles y altamente eficientes.
Consejo: Para profundizar en el uso de las funciones de
dplyr, se recomienda consultar los enlaces a los sitios oficiales disponibles en la sección de bibliografía al final de este capítulo.
6.7 El operador pipe (%>% y |>)
El operador de tubería o pipe permite encadenar o combinar múltiples operaciones de manera clara y legible. En lugar de escribir funciones anidadas, el resultado de una operación se utiliza directamente como entrada de la siguiente. Existen actualmente dos versiones:
%>%— es el pipe original del paquetemagrittr, incorporado al tidyverse. Es el más utilizado históricamente y el que se observa en la mayoría de los libros y tutoriales de R.|>— es el pipe nativo de R, disponible desde la versión 4.1.0 sin necesidad de cargar ningún paquete adicional. Su comportamiento es muy similar al anterior y representa la dirección actual del lenguaje.
Ambos operadores toman el resultado de lo que está a la izquierda y lo pasan como primer argumento a la función de la derecha, permitiendo construir cadenas de operaciones que se leen de izquierda a derecha y de arriba hacia abajo, pudiendo interpretarse el pipe como “luego” o “entonces”.
En este libro utilizaremos el pipe original (%>%), aunque en la práctica ambos son intercambiables en la mayoría de los casos.
Consejo: se recomienda utilizar el atajo de teclado para mejorar la velocidad de escritura. Para insertar un pipe deberá utilizar las teclas:
Ctrl + Shift + M
6.8 Primeros pasos con dplyr
A continuación veremos cómo aplicar los principales verbos de dplyr sobre el dataset PlantGrowth.
6.8.1 Filtrar filas con filter()
Seleccionamos solo las observaciones del tratamiento 1 (trt1):
## weight group
## 1 4.81 trt1
## 2 4.17 trt1
## 3 4.41 trt1
## 4 3.59 trt1
## 5 5.87 trt1
## 6 3.83 trt1
## 7 6.03 trt1
## 8 4.89 trt1
## 9 4.32 trt1
## 10 4.69 trt16.8.2 Ordenar filas con arrange()
Ordenamos de mayor a menor la variable weight (peso):
## weight group
## 1 6.31 trt2
## 2 6.15 trt2
## 3 6.11 ctrl
## 4 6.03 trt1
## 5 5.87 trt1
## 6 5.80 trt2
## 7 5.58 ctrl
## 8 5.54 trt2
## 9 5.50 trt2
## 10 5.37 trt2
## 11 5.33 ctrl
## 12 5.29 trt2
## 13 5.26 trt2
## 14 5.18 ctrl
## 15 5.17 ctrl
## 16 5.14 ctrl
## 17 5.12 trt2
## 18 4.92 trt2
## 19 4.89 trt1
## 20 4.81 trt1
## 21 4.69 trt1
## 22 4.61 ctrl
## 23 4.53 ctrl
## 24 4.50 ctrl
## 25 4.41 trt1
## 26 4.32 trt1
## 27 4.17 ctrl
## 28 4.17 trt1
## 29 3.83 trt1
## 30 3.59 trt16.8.3 Seleccionar columnas con select()
Seleccionamos solo la columna weight de la base de datos:
## weight
## 1 4.17
## 2 5.58
## 3 5.18
## 4 6.11
## 5 4.50
## 6 4.616.8.4 Renombrar variables con rename()
Renombramos las variables originales al español en un objeto nuevo “PlantGrowth_es”
## peso tratamiento
## 1 4.17 ctrl
## 2 5.58 ctrl
## 3 5.18 ctrl
## 4 6.11 ctrl
## 5 4.50 ctrl
## 6 4.61 ctrl6.8.5 Crear nuevas variables con mutate()
Creamos una nueva variable peso_mg con la variable peso:
## peso tratamiento peso_mg
## 1 4.17 ctrl 4170
## 2 5.58 ctrl 5580
## 3 5.18 ctrl 5180
## 4 6.11 ctrl 6110
## 5 4.50 ctrl 4500
## 6 4.61 ctrl 46106.8.6 Obtener medidas de resumen con summarise()
Una de las tareas más recurrentes en el análisis de datos es el cálculo de estadísticos o medidas de resumen. Estos indicadores son valores numéricos únicos que sintetizan una gran cantidad de observaciones, permitiendo describir a un conjunto de datos.
En el flujo de trabajo con el paquete dplyr, estas medidas se obtienen a través de funciones que se ejecutan dentro del verbo summarise() (o su variante summarize()). Por ejemplo, al declarar summarise(promedio = mean(variable_en_estudio)), estamos indicando a R que aplique la función de resumen mean() sobre una variable en estudio de interés y asigne el resultado a una nueva columna que se llamará promedio.
Como se observa en el siguiente bloque de código, la función summarise() recibe un dataframe y devuelve un nuevo objeto (generalmente un tibble) de una sola fila, donde cada columna representa un estadístico calculado:
# Promedio general de todas las plantas
PlantGrowth_es %>%
summarise(media_general = mean(peso, na.rm = TRUE))## media_general
## 1 5.073Medidas de resumen
Una de las tareas más recurrentes es el cálculo de estadísticos descriptivos. En la Tabla 6.1 se detallan las funciones más utilizadas dentro de summarise().
| Función | Medida de resumen |
|---|---|
n() |
Tamaño muestral (N) |
mean() |
Media aritmética |
median() |
Mediana |
sd() |
Desviación estándar |
var() |
Varianza |
min() / max() |
Mínimo y Máximo |
IQR() |
Rango intercuartílico |
Nota: Por defecto, estas funciones devuelven como resultado
NA(Not Available) si existe al menos un dato faltante en el vector. Para evitar esto y calcular el estadístico con los datos disponibles, deberá incluir siempre el argumentona.rm = TRUE(por ejemplo:mean(peso, na.rm = TRUE)).
6.8.7 Agrupación de datos con group_by()
En el análisis estadístico, es poco frecuente que un único valor de resumen sea suficiente para obtener conclusiones valiosas del conjunto de datos. Habitualmente, el interés principal radica en comparar cómo se comportan diferentes categorías o grupos dentro de una misma población, muestra o ensayo agrícola (por ejemplo, resultados por zonas geográficas, períodos temporales o tratamientos experimentales).
Para este propósito utilizamos la función group_by(). Esta herramienta permite “agrupar” las observaciones en función de los valores de una variable categórica (factor). Es fundamental destacar que esta función no modifica la tabla de datos en sí misma: no elimina filas ni altera los valores existentes. En cambio, crea una estructura interna (metadatos) que le indica a R: “de ahora en adelante, cualquier operación se realizará de forma independiente para cada grupo”.
Si ejecutamos el siguiente código, observaremos que la tabla parece idéntica a la original, pero en el encabezado de la consola aparecerá una línea adicional indicando los grupos detectados:
# Al ejecutar esto, observá la etiqueta "# Groups: tratamiento [3]" en la consola
PlantGrowth_es %>%
group_by(tratamiento)## # A tibble: 30 × 3
## # Groups: tratamiento [3]
## peso tratamiento peso_mg
## <dbl> <fct> <dbl>
## 1 4.17 ctrl 4170
## 2 5.58 ctrl 5580
## 3 5.18 ctrl 5180
## 4 6.11 ctrl 6110
## 5 4.5 ctrl 4500
## 6 4.61 ctrl 4610
## 7 5.17 ctrl 5170
## 8 4.53 ctrl 4530
## 9 5.33 ctrl 5330
## 10 5.14 ctrl 5140
## # ℹ 20 more rows6.8.8 Combinar group_by() con summarise()
Al combinar la función group_by() junto con summarise(), se obtienen medidas de resumen segmentadas por grupo, categoría o tratamiento. Esta sinergia consolida los resultados en una tabla sintética y comparativa, facilitando la interpretación. Veamos el siguiente ejemplo:
# Cálculo de medidas de resumen por tratamiento
resumen_tratamientos <- PlantGrowth_es %>%
group_by(tratamiento) %>%
summarise(
n = n(),
media = mean(peso, na.rm = TRUE),
desvio = sd(peso, na.rm = TRUE)
)
resumen_tratamientos## # A tibble: 3 × 4
## tratamiento n media desvio
## <fct> <int> <dbl> <dbl>
## 1 ctrl 10 5.03 0.583
## 2 trt1 10 4.66 0.794
## 3 trt2 10 5.53 0.4436.9 Aplicación conjunta: integrando los verbos
Hasta aquí hemos analizado cada función de manera independiente. Sin embargo, la verdadera potencia del tidyverse radica en la posibilidad de encadenar múltiples operaciones mediante el uso del pipe (%>%).
Este flujo nos permite leer el código de forma secuencial, como si fuera una receta, evitando la creación de múltiples objetos intermedios y reduciendo la posibilidad de errores. A continuación, integraremos distintos verbos para manipular los datos de PlantGrowth:
# Vamos a crear el objeto denominado "resumen_ensayo"
resumen_ensayo <- PlantGrowth %>%
rename(peso = weight, tratamiento = group) %>% # renombra las variables originales
mutate(peso_mg = peso * 1000) %>% # Convierte las unidades de gramos a miligramos
group_by(tratamiento) %>% # agrupar por tratamiento
summarise( # Calcula las medidas de resumen
n = n(),
promedio = mean(peso_mg, na.rm = TRUE),
desvio_std = sd(peso_mg, na.rm = TRUE)
)
resumen_ensayo # Visualizar el objeto resultante## # A tibble: 3 × 4
## tratamiento n promedio desvio_std
## <fct> <int> <dbl> <dbl>
## 1 ctrl 10 5032 583.
## 2 trt1 10 4661 794.
## 3 trt2 10 5526 443.Como se observa en el resultado obtenido a partir del bloque de código precedente, hemos construido una secuencia de trabajo lógico y ordenado. Este proceso puede ser desglosado de la siguiente manera:
Asignación: Primero, se define un objeto denominado
resumen_ensayopara almacenar el resultado.Traducción: Mediante el uso de
rename(), traducimos los nombres originales de las variables al español (pesoytratamiento).Transformación: A través de
mutate(), realizamos una conversión de unidades, transformando el peso de gramos a miligramos.Agrupación: Con
group_by(), establecemos la estructura interna necesaria para que los cálculos posteriores se realicen por tratamiento y no sobre el total.Síntesis estadística: Finalmente, se utiliza
summarise()para obtener las medidas descriptivas de interés: promedio, desvío estándar y número de observaciones.
6.10 Paquetes para Análisis Exploratorio de Datos (EDA)
Hasta este punto, hemos utilizado la función summarise() para obtener medidas de resumen que permitan complementar el análisis descriptivo. Si bien las funciones de dplyr proporcionan un control exhaustivo sobre el procesamiento y la síntesis de la información, R dispone de librerías especializadas para el Análisis Exploratorio de Datos (EDA, por sus siglas en inglés), que automatizan la generación de informes descriptivos detallados. Dos de las más utilizadas son:
summarytools: Se destaca por su capacidad para generar cuadros de estadísticos descriptivos con un formato profesional y estético. La funcióndescr()permite obtener medidas de posición y dispersión detalladas, mientras quedfSummary()produce un informe exhaustivo del dataframe, incluyendo frecuencias y distribuciones de cada variable.skimr: Proporciona una síntesis integral de las propiedades de los datos. Su principal ventaja es la generación de un resumen que incluye indicadores de centralidad y dispersión, junto con representaciones gráficas minimalistas que permiten evaluar la forma de la distribución directamente en la consola.
6.11 Otros paquetes aliados
Además de dplyr, existen otros paquetes que complementan la etapa de ordenar y transformar datos. A continuación se presentan brevemente algunos de los más utilizados.
6.11.1 tidyr
El paquete tidyr forma parte del tidyverse y está diseñado para ordenar y reorganizar la estructura de los datos. Sus funciones más utilizadas son:
pivot_longer()— transforma datos de formato ancho a largo, convirtiendo múltiples columnas en filas. Es especialmente útil cuando cada tratamiento o variable de tiempo ocupa una columna separada.pivot_wider()— realiza la operación inversa, convirtiendo filas en columnas. Permite pasar de un formato largo a uno ancho.drop_na()— elimina las filas que contienen valores faltantes (NA), facilitando la limpieza inicial del dataset.
6.11.2 janitor
Este paquete no forma parte del tidyverse pero es ampliamente utilizado para la limpieza inicial de datos. Sus funciones más destacadas son:
clean_names()— estandariza los nombres de las columnas, convirtiéndolos a minúsculas y reemplazando espacios y caracteres especiales por guiones bajos. Muy útil cuando se importan archivos de Excel con nombres de columnas irregulares.get_dupes()— identifica y aísla rápidamente las filas duplicadas en un conjunto de datos, lo que facilita examinar y gestionar los registros repetidos.remove_empty()— elimina filas y/o columnas completamente vacías del dataset.
6.11.3 naniar
El paquete naniar está especializado en el análisis, visualización e imputación básica de datos faltantes (NA). Sus funciones más útiles son:
Exploración y visualización:
miss_var_summary()— genera una tabla con el número y porcentaje de valores faltantes por variable, siendo el punto de partida ideal para evaluar la calidad del dataset antes del análisis.vis_miss()— genera una visualización gráfica del patrón de datos faltantes en el dataset, permitiendo identificar rápidamente qué variables y observaciones tienen valores ausentes.gg_miss_var()— muestra un gráfico de barras con el porcentaje de valores faltantes por variable.replace_with_na()— permite reemplazar valores específicos (como-999o"ND") porNA, estandarizando la representación de datos faltantes.
Imputación básica:
impute_mean()— reemplaza los valoresNA(Not Available) por la media de la variable.impute_median()— reemplaza los valoresNA(Not Available) por la mediana de la variable.
Consejo: Para profundizar en el uso de estas herramientas, se recomienda consultar los enlaces a los sitios oficiales disponibles en la sección de bibliografía al final de este capítulo.
El dominio de estas herramientas permite preparar los datos de manera adecuada para las etapas posteriores del análisis, particularmente para la visualización y el modelado estadístico.
6.12 Bibliografía y sitios de interés
Para ampliar la información, se recomienda consultar: