5 Importación de datos
5.1 ¿Qué es la importación de datos?
La importación es el primer paso en el flujo de trabajo en R (Figura 5.1), ya que permite integrar datos provenientes de diversas fuentes en el entorno de trabajo.
En este capítulo, se presentan dos paquetes fundamentales en R para la importación: readr y readxl. Ambos paquetes ofrecen soluciones efectivas para cargar datos en diferentes formatos y proporcionan funciones que simplifican el proceso de lectura, facilitando el análisis posterior. Al trabajar con estos paquetes, se puede optimizar el flujo de trabajo, mejorando la eficiencia y reduciendo posibles errores durante la carga de datos.
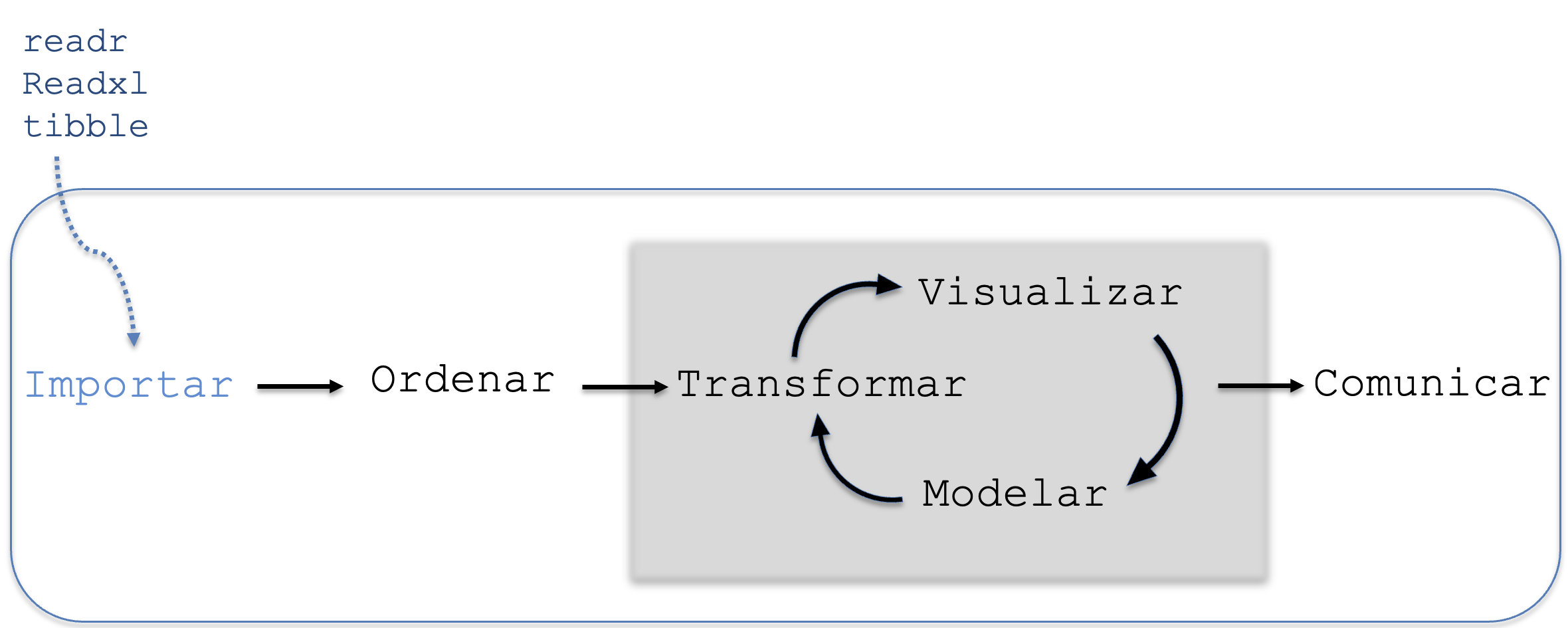
Figura 5.1: Etapa de importación de datos.
5.2 Instalación y carga de paquetes
Antes de comenzar, debemos asegurarnos de tener instalados y cargados los paquetes necesarios. Recuerde que la instalación solo es necesaria la primera vez, mientras que la carga con library() debe realizarse al inicio de cada sesión de trabajo.
5.3 Organización del entorno: Carpetas y archivos
Antes de importar los datos, es fundamental preparar nuestro entorno de trabajo. Como vimos en el Capítulo 2, al trabajar en un servidor remoto, R no puede acceder de forma directa a los archivos almacenados en tu computadora local; por lo tanto, es requisito indispensable cargarlos previamente en el espacio de trabajo del proyecto.
Sin embargo, no basta con subirlos: la organización es la base de un flujo de trabajo eficiente. Mantener el orden desde el primer día es fundamental en R. Si permitimos que los archivos se acumulen de forma dispersa en el directorio principal, la gestión del proyecto se volverá confusa y propensa a errores a medida que el análisis crezca en complejidad.
Pasos para organizar el entorno:
Crear la carpeta: En la pestaña Files (Ventana 4), hacer clic en el botón New Folder y nombrar a la nueva carpeta como
datos(se recomienda usar siempre minúsculas y evitar espacios).Ingresar a la carpeta: Hacer clic sobre la carpeta
datosque acaba de crear para entrar en ella.Subir los archivos: Utilizar el botón Upload para cargar desde la computadora, los archivos (bases de datos, imágenes, etc.) que son de interés para trabajar y que serán importados a R.
Si no recuerda exactamente cómo es el proceso de carga de archivos, se sugiere repasar la sección Carga de archivos (Upload) del Capítulo 2.
5.3.1 El concepto de Ruta Relativa
Al organizar los archivos dentro de una carpeta, debemos indicarle a R exactamente dónde encontrarlos. Esto se hace mediante una ruta. Si el archivo está dentro de la carpeta datos, la forma de llamarlo dentro de la función de importación cambia ligeramente, anteponiendo el nombre de la carpeta. Por ejemplo:
5.4 Las bases de datos
Para ilustrar las diferentes técnicas de importación, trabajaremos con tres bases de datos que representan situaciones reales y habituales en el ámbito de las Ciencias Agrarias. Tener claro qué contiene cada archivo antes de importarlo es fundamental para verificar que la carga fue exitosa.
1. Ensayo de Maíz (maiz.csv)
Es un archivo de texto plano (CSV) que utilizaremos para la importación local. Contiene datos de un ensayo de fertilización nitrogenada en el cultivo de maíz. Las variables que contiene son:
DOSIS_N: Cantidad de nitrógeno aplicada (en kg/ha).
DIAMETRO_TALLO: Medición del grosor del tallo (en mm).
2. Dinámica de Nitrógeno (nitrogeno)
Este archivo se encuentra alojado en la nube (Google Sheets). Lo utilizaremos para aprender a conectar R con datos remotos. Representa un muestreo de suelo por horizontes. Sus variables son:
REPETICION: Identificador de las 4 repeticiones por profundidad.
PROFUNDIDAD: Nivel de profundidad del muestreo (en cm).
NITROGENO: Porcentaje de nitrógeno total hallado en la muestra (%).
3. Comparación de parámetros en dos variedades de Mandarinas (mandarinas.xlsx)
Esta base de datos integra variables cuantitativas y cualitativas que permiten comparar el desempeño de dos variedades comerciales de mandarina y constituye un ejemplo real de evaluación de parámetros productivos y de calidad en cítricos de nuestra región.
Agradecimiento: Esta base de datos fue obtenida por los estudiantes de segundo año que cursaron la asignatura Estadística y Biometría de la carrera de Ingeniería Agronómica de la FCA - UNCA. Se agradece profundamente su dedicación y esmero en la recopilación de estos datos, los cuales formaron parte esencial del desarrollo práctico del cursado de la asignatura.
Las variables que procesaremos en este archivo son:
GRUPO: Identificador del grupo de estudiantes que recopiló los datos.
VARIEDAD: Variedad comercial (Clementina o Criolla).
PESO: Peso individual del fruto (en g).
DIAM_ECUAT: Diámetro ecuatorial del fruto (en mm).
NIVEL_DE_DAÑO: Escala de daño externo detectado (0 a 3).
COLOR: Índice visual de coloración de la cáscara.
Importante: para realizar las actividades de este capítulo, deberá descargar los archivos de práctica (
maiz.csvymandarinas.xlsx) que se encuentran alojados en la carpetadatosde la sección Sobre este libro.
5.5 Paquete readr
![]()
El paquete readr es una herramienta para importar archivos de datos en diversos formatos. Su principal ventaja es que proporciona una interfaz simplificada y consistente, permitiendo leer archivos de texto delimitado, especialmente en formato “.csv”. Incluye un manejo robusto de los tipos de datos, convirtiendo automáticamente las columnas al tipo más apropiado en R y facilitando así el análisis de datos.
Este paquete forma parte del tidyverse, por lo que al correr la función library(tidyverse) queda disponible automáticamente sin necesidad de cargarlo por separado.
5.6 Función read_csv()
La función read_csv() del paquete readr es una herramienta rápida y eficiente para la importación de archivos en formato CSV (Comma-Separated Values). Es especialmente valorada en proyectos que requieren una carga ágil de grandes volúmenes de datos, ya que ofrece mejoras significativas en la velocidad de carga y en la gestión de la memoria de la computadora en comparación con las funciones básicas de R.
Una característica fundamental de esta función es que asigna automáticamente tipos de datos a cada columna y genera objetos de tipo tibble. El tibble es una versión moderna del tradicional data.frame, optimizada para funcionar dentro del tidyverse, lo que facilita enormemente las etapas posteriores de manipulación y visualización.
5.6.1 Importar un archivo CSV local
Para leer un archivo que ha sido subido previamente a la carpeta datos de nuestro proyecto en Posit Cloud, utilizamos la función read_csv(). Como argumento principal, indicamos entre comillas la ruta relativa (carpeta y nombre del archivo con su extensión). El resultado de esta operación debe asignarse a un objeto para poder trabajar con él.
# Importamos la base de datos maíz guardada en la carpeta "datos"
MAIZ <- read_csv("datos/maiz.csv")## Rows: 50 Columns: 2
## ── Column specification ───────────────────────────
## Delimiter: ","
## dbl (2): DOSIS_N, DIAMETRO_TALLO
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Una vez importados los datos, es una buena práctica realizar una exploración inicial con la función head(). Esto nos permite visualizar las primeras seis filas del conjunto de datos y verificar que la estructura, los nombres de las columnas y los valores se hayan cargado correctamente:
## # A tibble: 6 × 2
## DOSIS_N DIAMETRO_TALLO
## <dbl> <dbl>
## 1 0 8.37
## 2 0 11.5
## 3 0 10.4
## 4 0 7.74
## 5 0 9.13
## 6 0 12.5
Importante: R distingue entre mayúsculas y minúsculas. Si el objeto se llama “MAIZ”, deberá escribirlo siempre de esa manera; de lo contrario, el programa arrojará un error de “objeto no encontrado”.
5.6.2 Importar un archivo CSV desde la web
Una de las ventajas de la función read_csv() es su capacidad para conectar directamente con archivos alojados en la nube, incluyendo bases de datos desarrolladas en Google Sheets. Este método facilita el trabajo colaborativo y asegura la reproducibilidad, ya que permite que R lea siempre la versión más actualizada de los datos sin necesidad de descargas manuales intermedias.
Para lograr esto, el archivo original en Google Sheets debe estar configurado como “Publicado en la web” en formato CSV. Esto genera un enlace público del archivo al cual se le debe adicionar el parámetro ?output=csv al final de la URL, permitiendo que R lo interprete como una tabla de datos pura.
En el siguiente ejemplo, se utilizará la base de datos denominada nitrogeno, que puede ser visualizada a través del siguiente enlace.
Para poder importar esta información a nuestro entorno de trabajo, ejecutamos el siguiente bloque de código:
# Importación directa mediante URL pública de Google Sheets
NITROGENO <- read_csv("https://docs.google.com/spreadsheets/d/e/2PACX-1vRGuSZ7KkeaPmXqmAGK1f6CXMHYaLarcWs0WxD36cmuAOHAffAkRo2lD4PDZHg68gbLKN5gA5fkS28n/pub?output=csv")Para verificar que la estructura se haya cargado correctamente y conocer el nombre exacto de las variables disponibles en el objeto, se utilizará la función names():
## [1] "REPETICION" "PROFUNDIDAD" "NITROGENO"5.6.3 Función read_csv2()
Es importante conocer la función read_csv2(), también perteneciente al paquete readr. Esta función está diseñada para leer archivos CSV que utilizan el punto y coma (;) como separador de columnas y la coma (,) como separador decimal.
Este formato es muy común en archivos exportados desde Excel en sistemas configurados en español. En estos sistemas, la coma es el separador decimal por defecto y, por lo tanto, no puede usarse simultáneamente para delimitar las columnas.
Si al importar un archivo CSV con read_csv() los datos aparecen todos en una sola columna en la consola de R, es probable que el archivo use punto y coma como separador. En ese caso, utilice read_csv2():
5.7 Paquete readxl

El paquete readxl, a diferencia de readr, no forma parte del tidyverse, por lo que debe instalarse y cargarse de manera independiente con library(readxl). Tenga en cuenta que esta acción ya fue realizada en la sección de Instalación y carga de paquetes al inicio del presente capítulo.
Se utiliza en R para importar hojas de cálculo en formatos .xls y .xlsx. Permite leer archivos almacenados localmente o en la nube, y ofrece la posibilidad de trabajar con distintas hojas de un mismo archivo mediante el argumento sheet.
Resulta especialmente útil cuando los datos provienen de Excel o Google Sheets, sin necesidad de convertirlos a otros formatos y preservando la estructura original de las celdas y columnas.
5.8 Función read_excel()
La función read_excel() es versátil y detecta automáticamente si el archivo se encuentra en un formato antiguo (.xls) o uno moderno (.xlsx). Para utilizarla, el archivo debe estar previamente cargado en la carpeta datos de nuestro proyecto en Posit Cloud o la versión de escritorio de RStudio.
5.8.1 Importar la primera hoja de un archivo Excel
Por defecto, la función read_excel() importa automáticamente la primera hoja del archivo. Al igual que en los casos anteriores, se indica la ruta y el nombre del archivo entre comillas como argumento de la función y se asigna el resultado a un objeto:
# Importamos la base de datos "mandarinas" desde la carpeta datos
MANDARINAS <- read_excel("datos/mandarinas.xlsx")Al igual que las funciones de readr, read_excel() devuelve los datos en formato tibble. Esto asegura que la base de datos se integre perfectamente con las herramientas de manipulación y visualización que veremos más adelante.
5.8.1.1 Exploración inicial con glimpse()
Para completar el diagnóstico inicial de los datos, utilizamos la función glimpse(), que pertenece al paquete dplyr. Mientras que la función names() nos dio la lista de variables y head() nos permitió ver las primeras filas, glimpse() permite verificar, de un solo vistazo, el tipo de dato que R asignó a cada columna (por ejemplo: <dbl> para números decimales, <fct> para factores o <chr> para texto), junto con una muestra de los primeros valores de cada variable incluida en el set de datos.
## Rows: 419
## Columns: 8
## $ N <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
## $ GRUPO <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ VARIEDAD <chr> "Clementina", "Clementina", "Clementina", "Clementina", …
## $ N_DE_FRUTO <dbl> 19, 9, 21, 8, 4, 30, 22, 23, 17, 27, 29, 14, 16, 13, 25,…
## $ PESO <dbl> 101, 122, 127, 126, 37, 139, 140, 130, 138, 142, 121, 15…
## $ DIAM_ECUAT <dbl> 64.2, 64.2, 64.7, 64.9, 65.9, 66.4, 67.1, 67.5, 68.2, 68…
## $ NIVEL_DE_DAÑO <dbl> 1, 0, 3, 3, 2, 2, 3, 1, 2, 2, 2, 1, 1, 2, 1, 1, 0, 1, 0,…
## $ COLOR <dbl> 4, 5, 4, 1, 5, 4, 4, 3, 3, 4, 4, 1, 1, 3, 4, 1, 4, 1, 5,…Al utilizar estas tres herramientas en conjunto —names(), head() y glimpse(), nos aseguramos de que R ha interpretado correctamente nuestra planilla de campo (especialmente los separadores decimales y las categorías) antes de iniciar cualquier análisis estadístico profundo.
5.8.2 Importar una hoja específica con sheet
Por defecto, la función read_excel() siempre importará la primera hoja que encuentre en el archivo. Sin embargo, si el archivo de Excel tiene varias pestañas, se puede especificar cuál se quiere cargar agregando el argumento sheet = "nombre_de_la_hoja" dentro de los paréntesis.
También es posible indicar la posición de la hoja usando números (por ejemplo, sheet = 2 para la segunda pestaña), aunque lo más recomendable es usar el nombre exacto para evitar confusiones si el orden de las hojas cambia.
Si alguna vez no recuerda cómo se llaman las pestañas de un archivo, se puede consultar rápidamente con la función excel_sheets():
## [1] "Hoja 1" "Hoja 2"