8 Visualización II: Tipos de gráficos
8.1 Tipos de gráficos con ggplot2
En el capítulo anterior aprendimos los componentes fundamentales de ggplot2. En este capítulo aplicaremos esos conocimientos para construir siete tipos de gráficos esenciales en el análisis de datos, que permiten visualizar y explorar datos tanto categóricos como numéricos.
Desarrollaremos los siguientes gráficos:
Gráfico de barras
Gráfico de barras apiladas
Diagramas de dispersión
Gráfico de líneas (series temporales)
Histogramas
Polígono de frecuencias
Gráfico de cajas y bigotes (Boxplot)
A continuación, presentaremos cada uno de ellos siguiendo el flujo de trabajo habitual, detallado en la Figura 8.1:
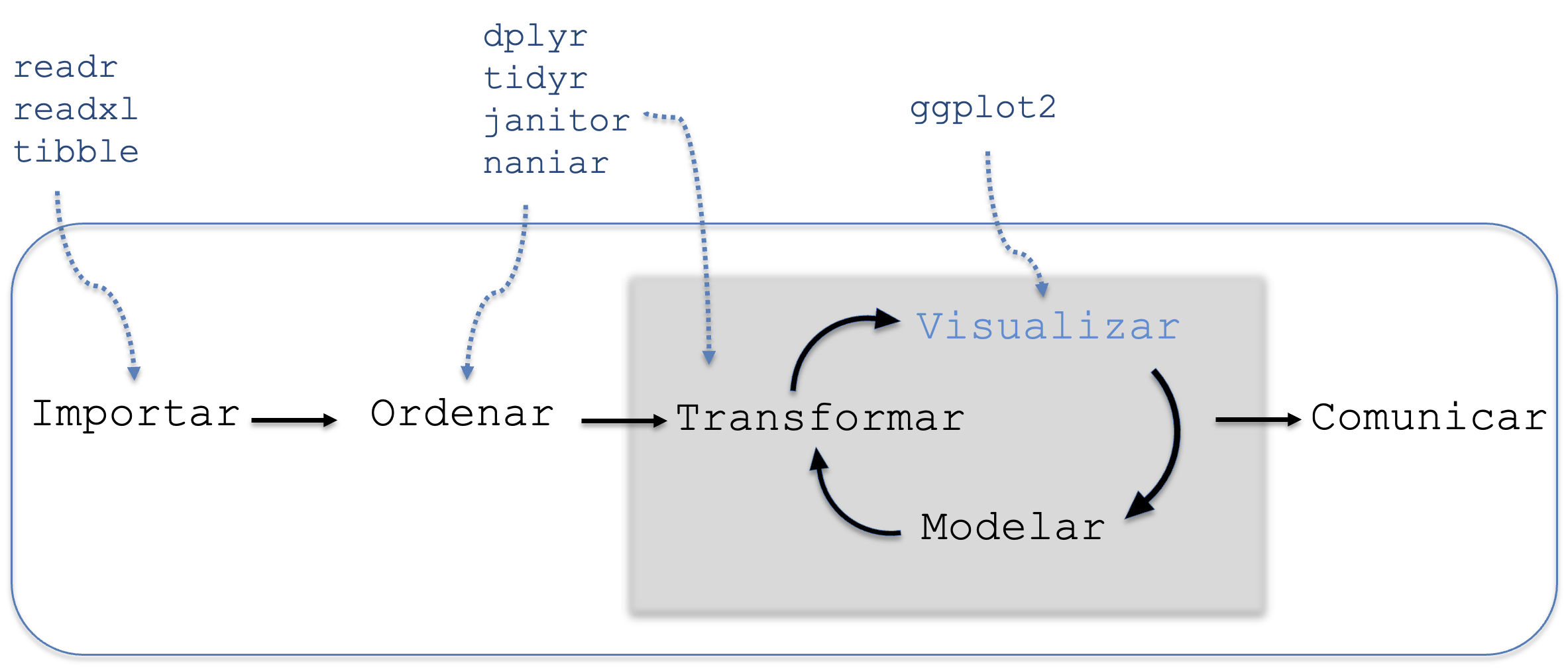
Figura 8.1: Etapa de visualización de datos.
8.2 Cargamos los paquetes
Para esta etapa, utilizaremos el tidyverse (que incluye ggplot2) y el paquete readxl para la importación de las planillas de Excel.
8.3 Las bases de datos
A lo largo de este capítulo, utilizaremos cuatro conjuntos de datos para explorar diferentes tipos de representaciones gráficas. Cada uno ha sido seleccionado por su estructura y por el tipo de variable que permite visualizar:
PlantGrowth: Es el dataset de crecimiento de plantas que venimos utilizando. Lo emplearemos principalmente para gráficos de barras y comparaciones de peso por tratamiento.iris: Una base de datos clásica en estadística que contiene mediciones de longitud y ancho de sépalos y pétalos de tres especies de flores (Iris setosa, Iris versicolor e Iris virginica ). Nos permitirá ejemplificar diagramas de dispersión y relaciones entre variables morfológicas.PP_77_22: Contiene registros históricos de precipitación anual en una localidad de la Provincia de Catamarca para el período 1977-2022. Esta serie temporal nos permitirá trabajar con gráficos de líneas. Este archivo, denominadoprecipitaciones.xlsx, será importado utilizando la funciónread_excel().MANDARINAS: Como se describió en el Capítulo 5, estos datos provienen de mediciones efectuadas en dos variedades de mandarina. Debido a su gran número de observaciones y variables, será nuestra base principal para construir histogramas, polígonos de frecuencia y gráficos de barras apiladas.
Importante: para realizar las actividades de este capítulo, deberá descargar los archivos de práctica (
precipitaciones.xlsxymandarinas.xlsx) que se encuentran alojados en la carpetadatosde la sección Sobre este libro.
A continuación, realizamos la carga y el procesamiento inicial de los datos (renombrado de variables y lectura de archivos):
# 1. PlantGrowth: Renombrado de variables al español
PlantGrowth_es <- PlantGrowth %>%
rename(peso = weight,
tratamiento = group)
# 2. Iris: Traducción de variables morfológicas
iris_es <- iris %>%
rename(long_sepalo = Sepal.Length,
ancho_sepalo = Sepal.Width,
long_petalo = Petal.Length,
ancho_petalo = Petal.Width,
especie = Species)
# 3. Precipitaciones: Importación y limpieza de nombres
PP_77_22 <- read_excel("datos/precipitaciones.xlsx") %>%
rename(anio = ANIO,
precipitacion = PP)
# 4. Mandarinas: Importación de la base de datos de la cátedra
MANDARINAS <- read_excel("datos/mandarinas.xlsx")8.4 Construcción de los gráficos
Una vez que el entorno está configurado y los datos han sido cargados y preparados, el siguiente paso es aplicar la gramática de capas de ggplot2 para dar forma a las visualizaciones. A continuación, se explora la sintaxis necesaria para construir cada uno de los gráficos fundamentales para el análisis de datos, partiendo desde representaciones de una sola variable hasta llegar a comparaciones más complejas.
8.4.1 Gráfico de barras
El gráfico de barras es uno de los recursos más habituales para visualizar la distribución de los datos. Se emplea principalmente para:
Visualizar la frecuencia de variables cualitativas (categorías) o cuantitativas discretas (conteos).
Comparar valores calculados o parámetros estadísticos (como el promedio) entre diferentes grupos o categorías.
¿geom_bar() o geom_col()?
La elección de la función que vamos a utilizar para elaborar el gráfico de barras depende de cómo se encuentren organizados los datos en nuestro marco de trabajo:
geom_col(): Se utiliza para representar valores específicos que ya existen en una columna. Es la opción adecuada cuando queremos graficar un valor que calculamos previamente (por ejemplo, la media de un grupo).geom_bar(): Se utiliza para mostrar el conteo o frecuencia de una variable. R cuenta automáticamente cuántas veces aparece cada categoría en el conjunto de datos.
Visualizar el promedio por grupo con geom_col()
En este ejemplo, utilizaremos el dataset PlantGrowth_es para comparar el peso promedio obtenido en diferentes grupos. Observe cómo integramos el procesamiento de datos con la visualización mediante el operador pipe (%>%):
PlantGrowth_es %>% # tomamos la base de datos
group_by(tratamiento) %>% # agrupamos por tratamiento
summarise(peso_promedio = mean(peso)) %>% # obtenemos el "peso promedio" por tratamiento
ggplot(aes(x = tratamiento, y = peso_promedio, fill = tratamiento)) + # graficamos
geom_col(alpha = 0.8) +
labs(title = "Peso promedio por tratamiento",
x = "Tratamiento",
y = "Peso promedio (g)",
fill = "Tratamiento") +
theme_classic()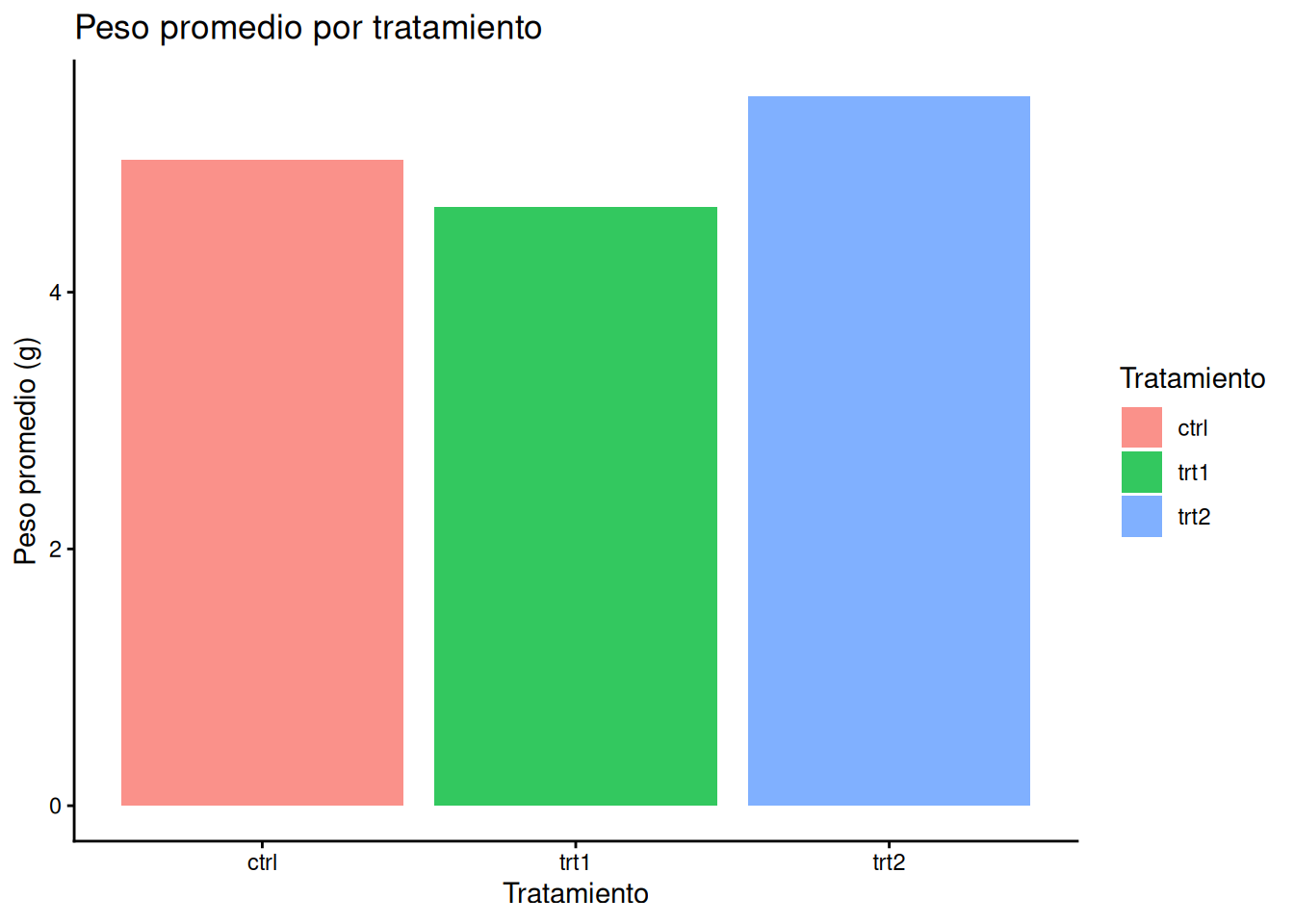
Visualizar la frecuencia de categorías con geom_bar()
Para este ejemplo, utilizaremos una combinación de funciones: primero filtramos la base con filter() seleccionando solo la variedad “Criolla” y luego generamos el gráfico con geom_bar().
Observe que, aunque el nivel de daño está registrado con números (0, 1, 2 y 3), lo trataremos como una categoría usando as.factor(). Esto evita que R lo interprete como una variable continua y nos permite ver una barra definida para cada nivel de daño.
# Filtramos para una sola variedad y graficamos la frecuencia de daños
MANDARINAS %>%
filter(VARIEDAD == "Criolla") %>%
ggplot(aes(x = as.factor(NIVEL_DE_DAÑO), fill = as.factor(NIVEL_DE_DAÑO))) +
geom_bar(alpha = 0.8) +
labs(title = "Distribución del nivel de daño en Mandarina Criolla",
subtitle = "Conteo de frutos según escala de daño (0 al 3)",
x = "Grado de daño",
y = "Cantidad de frutos (n)",
fill = "Nivel de daño") +
theme_minimal()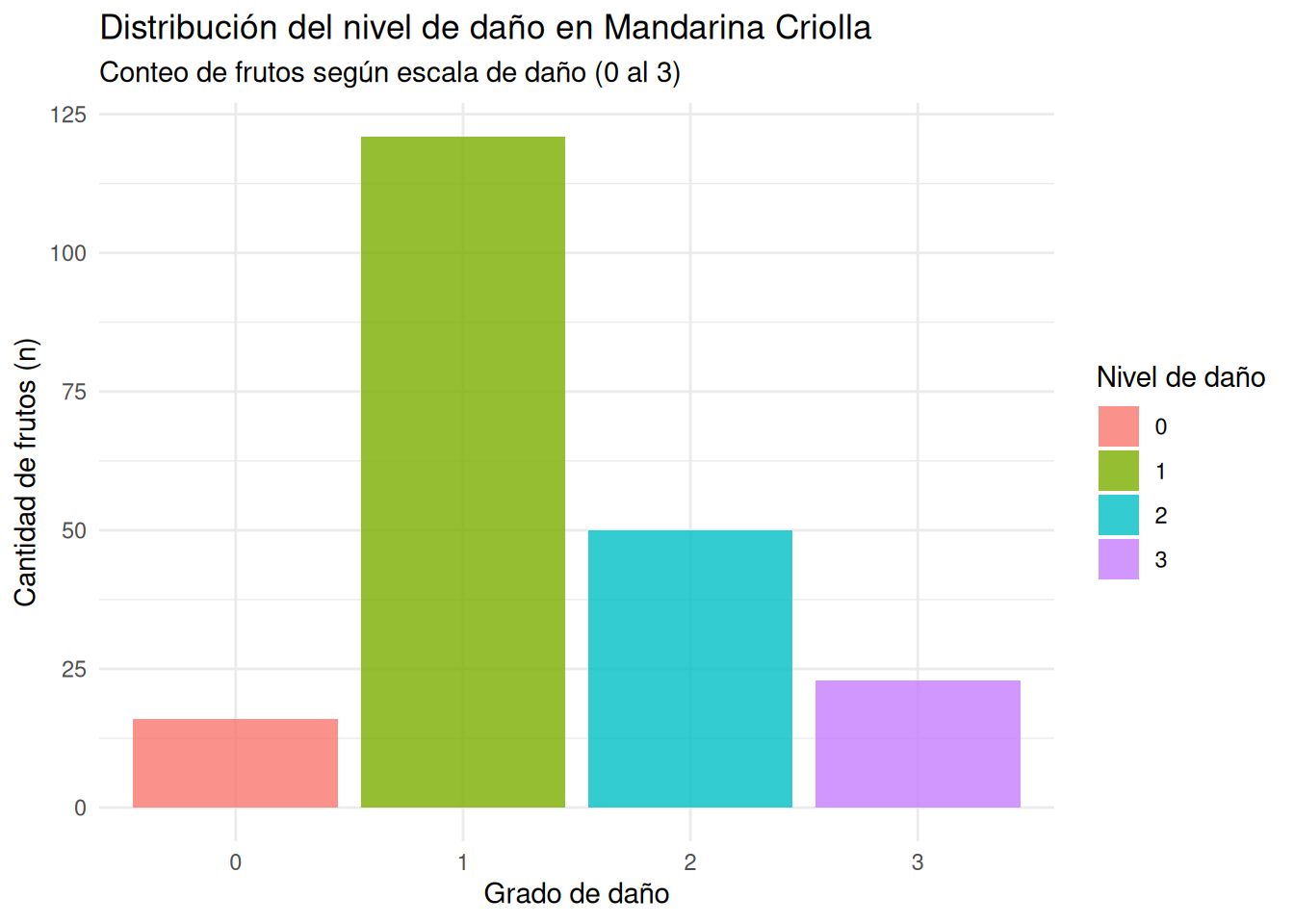
8.4.2 Gráfico de barras apiladas
El gráfico de barras apiladas es una extensión del gráfico de barras convencional. Se utiliza para mostrar la composición de una categoría principal mediante segmentos que representan subcategorías.
Para que este gráfico sea efectivo, necesitamos mapear una variable al eje x y otra variable diferente al argumento fill (relleno). En este caso, compararemos la proporción de daños entre las dos variedades de mandarinas.
Nota: Como la variable NIVEL_DE_DAÑO contiene números (0 a 3), utilizaremos
as.factor()para queggplot2la reconozca como una variable categórica. Esto permite asignar un color distinto a cada nivel de daño en lugar de una escala continua.
Barras segmentadas por frecuencias absolutas
Para construir este tipo de visualización, utilizamos la función geom_bar(), pero en este caso recurrimos específicamente al argumento position = "stack".
Este argumento le indica a R que, en lugar de colocar las barras una al lado de la otra, debe apilarlas verticalmente. De esta manera, cada segmento de la barra representa el conteo real (frecuencia absoluta) de una subcategoría, y la altura total de la barra coincide con el total de observaciones de la categoría principal.
Para que este gráfico funcione, es requisito indispensable definir dos variables en la estética (aes):
x: La variable que define las columnas principales (ej. Variedad).fill: La variable que divide cada columna en segmentos de colores (ej. Nivel de daño).
# Gráfico de barras apiladas mediante el argumento position = "stack"
ggplot(MANDARINAS, aes(x = VARIEDAD, fill = as.factor(NIVEL_DE_DAÑO))) +
geom_bar(position = "stack", alpha = 0.8) +
labs(title = "Composición de daños por variedad",
x = "Variedad de mandarina",
y = "Cantidad de frutos (n)",
fill = "Nivel de daño") +
theme_classic()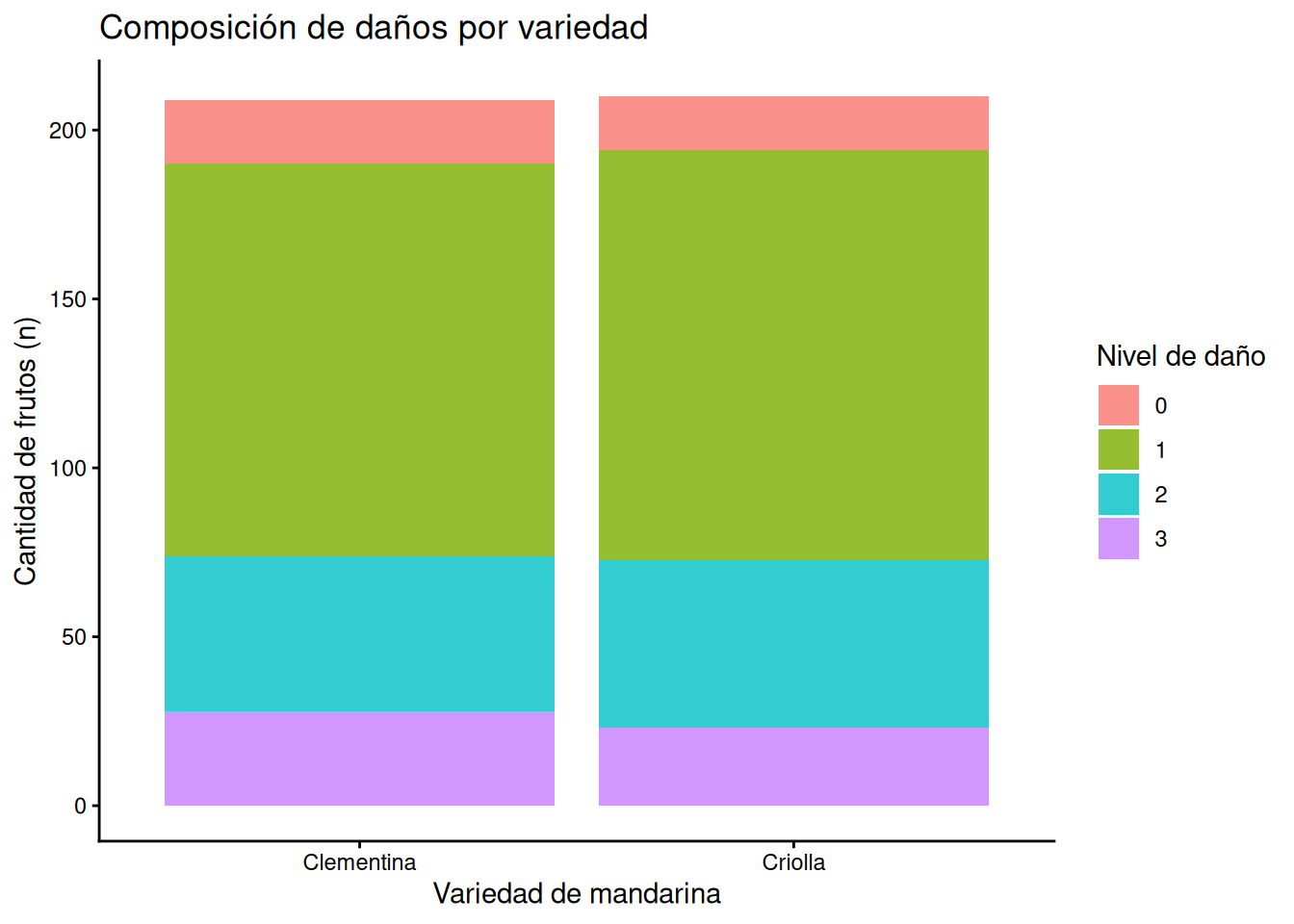
Barras segmentadas por frecuencias relativas
Al igual que en el caso anterior, para construir este gráfico utilizamos la función geom_bar(), pero esta vez recurrimos al argumento position = "fill".
Este argumento es fundamental cuando nuestro objetivo no es comparar cuántos datos hay en total, sino cómo se distribuyen internamente las categorías. Al usar "fill", R realiza dos operaciones automáticamente:
Calcula la proporción que cada subcategoría representa sobre el total de su grupo.
Normaliza todas las barras a una altura común de 1 (equivalente al 100%).
En el siguiente ejemplo de aplicación, observaremos que este tipo de representación gráfica permite comparar los perfiles de cada variedad de mandarina de forma directa, eliminando el sesgo producido por diferentes tamaños de muestra:
#Gráfico de barras apiladas mediante el argumento position = "fill"
ggplot(MANDARINAS, aes(x = VARIEDAD, fill = as.factor(NIVEL_DE_DAÑO))) +
geom_bar(position = "fill", alpha = 0.8) +
labs(title = "Distribución del nivel de daño por variedad de mandarina",
x = "Variedad de mandarina",
y = "Proporción",
fill = "Nivel de daño") +
theme_classic()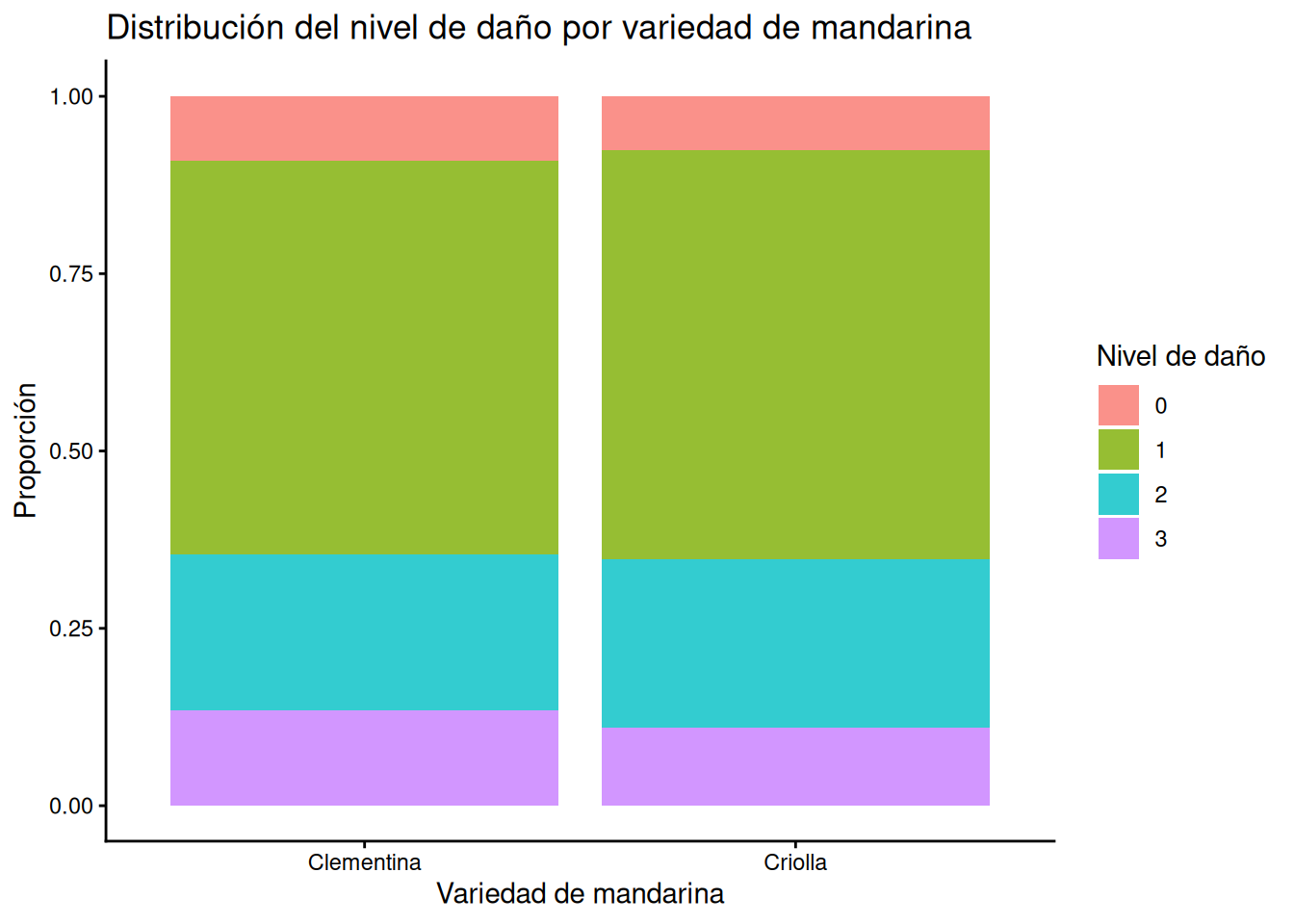
Cambio de orientación de las barras
En ocasiones, cuando las etiquetas del eje horizontal son largas o simplemente por preferencia estética, es útil girar el gráfico. La función coord_flip() intercambia los ejes x e y sin necesidad de modificar el mapeo de la estética.
# Aplicación de coord_flip para vista horizontal
ggplot(MANDARINAS, aes(x = VARIEDAD, fill = as.factor(NIVEL_DE_DAÑO))) +
geom_bar(position = "fill", alpha = 0.8) +
labs(title = "Distribución del nivel de daño por variedad de mandarina",
x = "Variedad",
y = "Proporción",
fill = "Nivel de daño") +
theme_classic() +
coord_flip()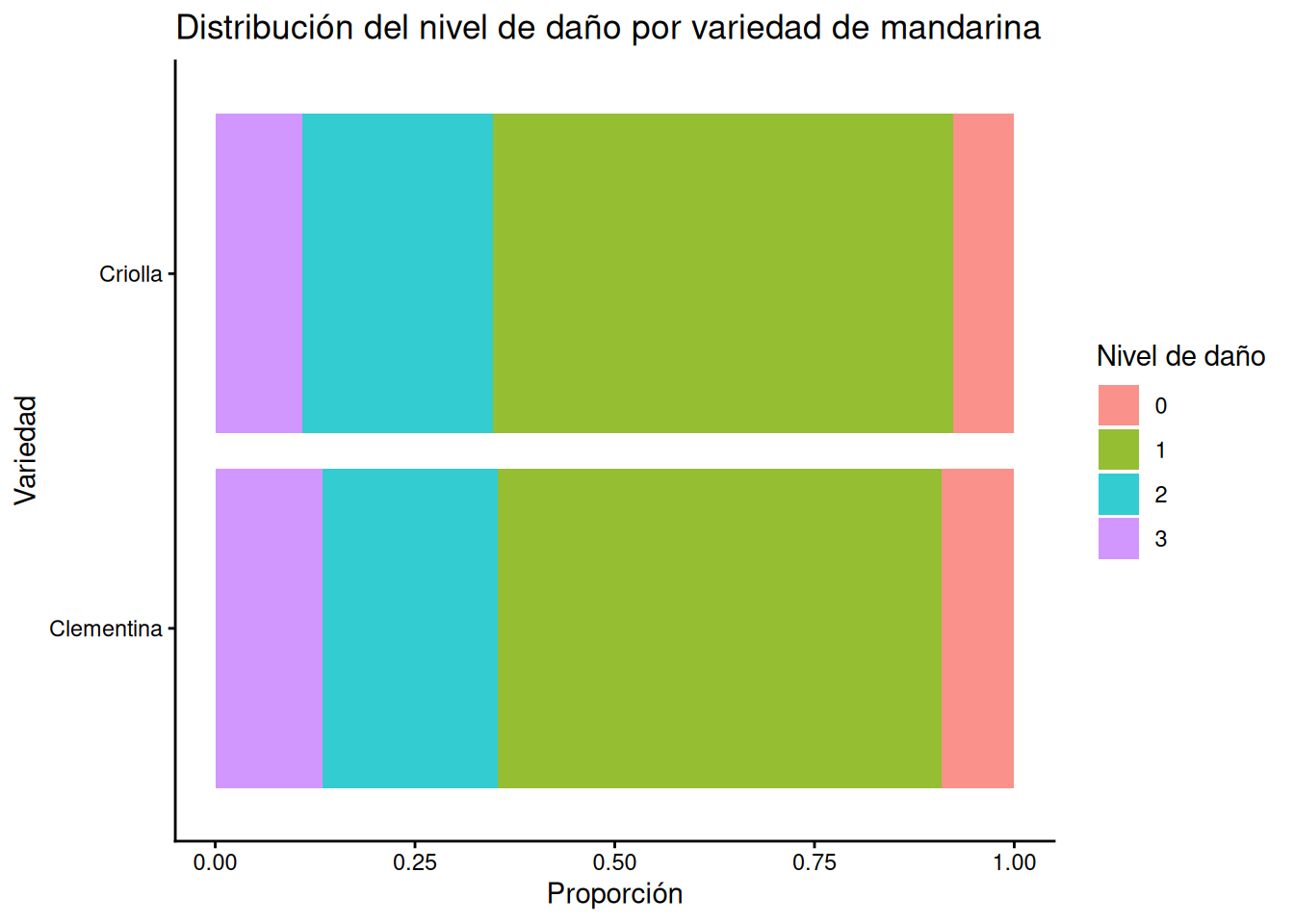
Nota: El sistema de coordenadas
coord_flip()es independiente del tipo de gráfico; puede ser utilizado en cualquier geometría (barras, cajas, líneas, etc.) para modificar la visualización.
8.4.3 Diagrama de dispersión
Los gráficos de dispersión o scatter plots se utilizan para mostrar la relación entre dos variables cuantitativas continuas, donde cada observación está representada por un punto en un sistema de coordenadas cartesianas. Para este gráfico utilizaremos el set de datos iris_es y recurriremos a la función: geom_point()
# Gráfico de dispersión básico
ggplot(iris_es, aes(x = long_petalo, y = ancho_petalo)) +
geom_point() +
labs(title = "Relación entre longitud y ancho de pétalos",
x = "Longitud del pétalo (cm)",
y = "Ancho del pétalo (cm)") +
theme_classic()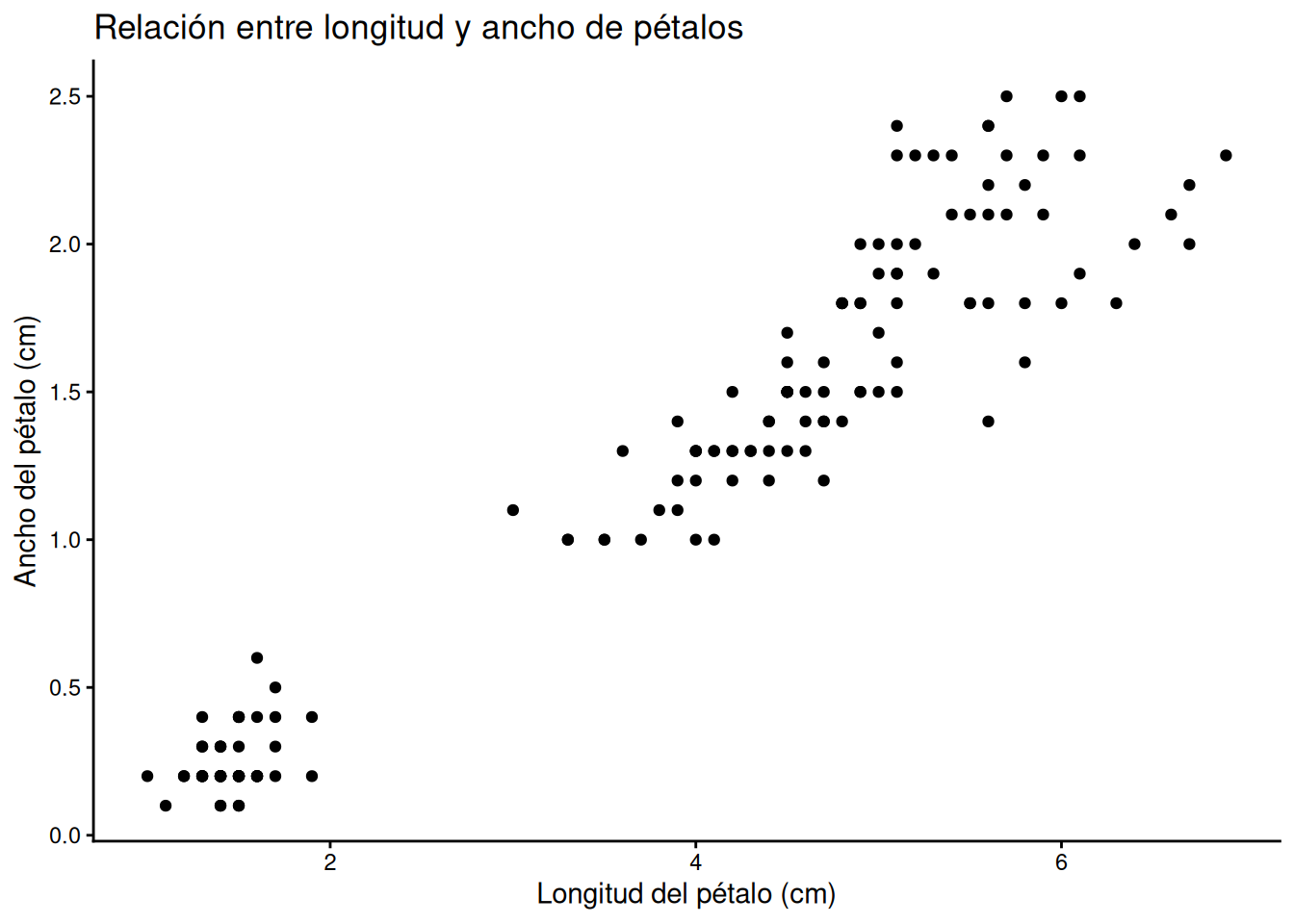
Personalización de la forma (shape)
Podemos reemplazar los puntos por diferentes formas geométricas utilizando el argumento shape. Como se observa Figura 8.2, R dispone de una amplia variedad de símbolos identificados por números:

Figura 8.2: Códigos numéricos para las formas de puntos en ggplot2.
Para aplicar una forma específica a todos los puntos, incluimos el argumento fuera de la estética (aes()):
# Dispersión con forma de triángulo invertido (shape 25)
ggplot(iris_es, aes(x = long_petalo, y = ancho_petalo)) +
geom_point(shape = 25, fill = "yellow", colour = "black") +
labs(title = "Dispersión con forma personalizada",
x = "Longitud del pétalo (cm)",
y = "Ancho del pétalo (cm)") +
theme_classic()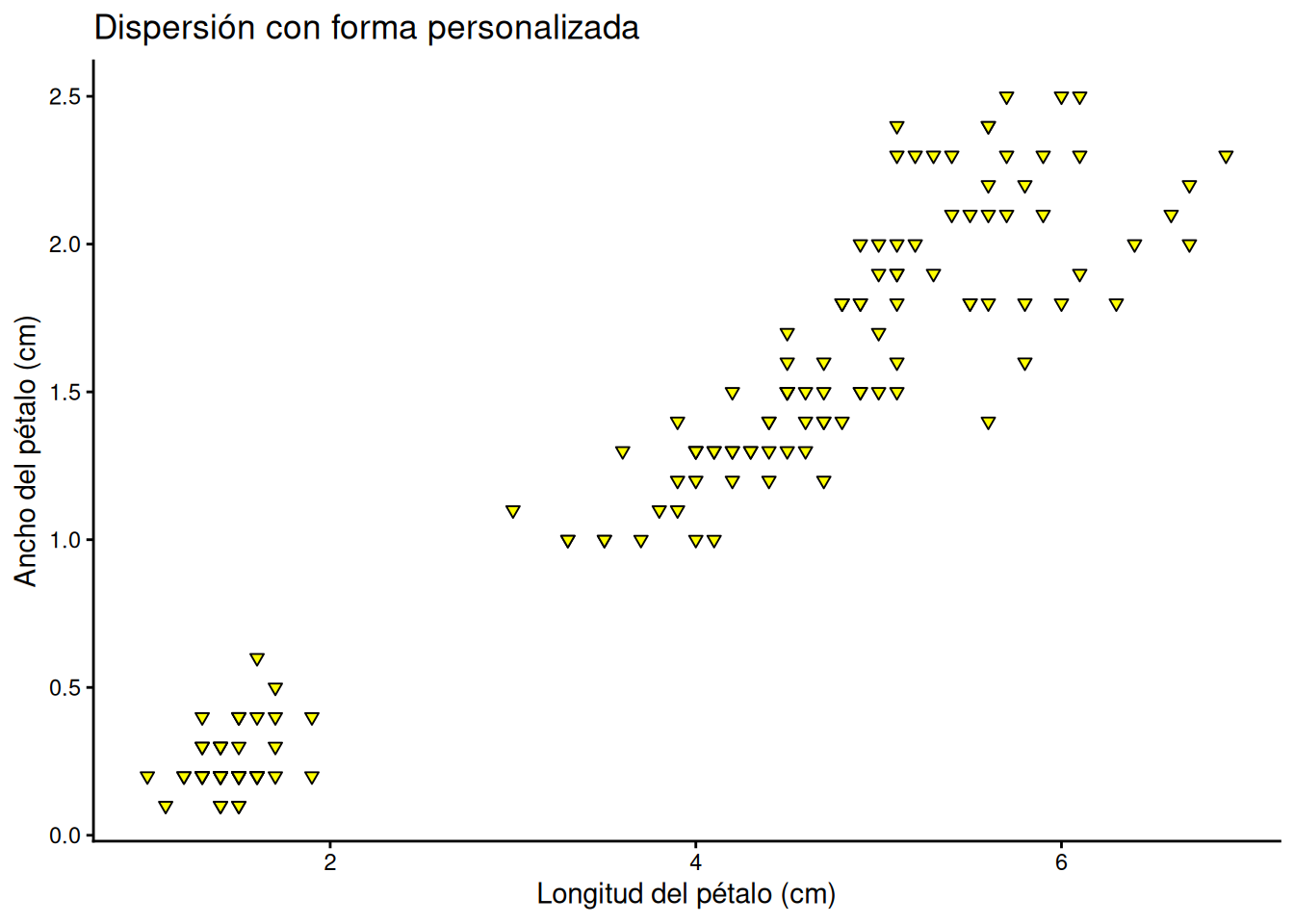
Nota: Para las formas numeradas del 21 al 25, el argumento
fillcontrola el color de relleno ycolourcontrola el color del borde. Para las demás formas, solo se utilizacolour.
Modificación de tamaño y color por grupos
Es posible mapear la forma, el tamaño y el color a una variable categórica para diferenciar grupos dentro de la misma nube de puntos. En este caso, observaremos cómo se agrupan las diferentes especies de flores:
# Dispersión segmentada por especie con múltiples atributos
ggplot(iris_es, aes(x = long_petalo, y = ancho_petalo,
shape = especie, colour = especie)) +
geom_point(size = 3) +
labs(title = "Morfología del pétalo según especie",
x = "Longitud del pétalo (cm)",
y = "Ancho del pétalo (cm)",
colour = "Especie",
shape = "Especie") +
theme_classic()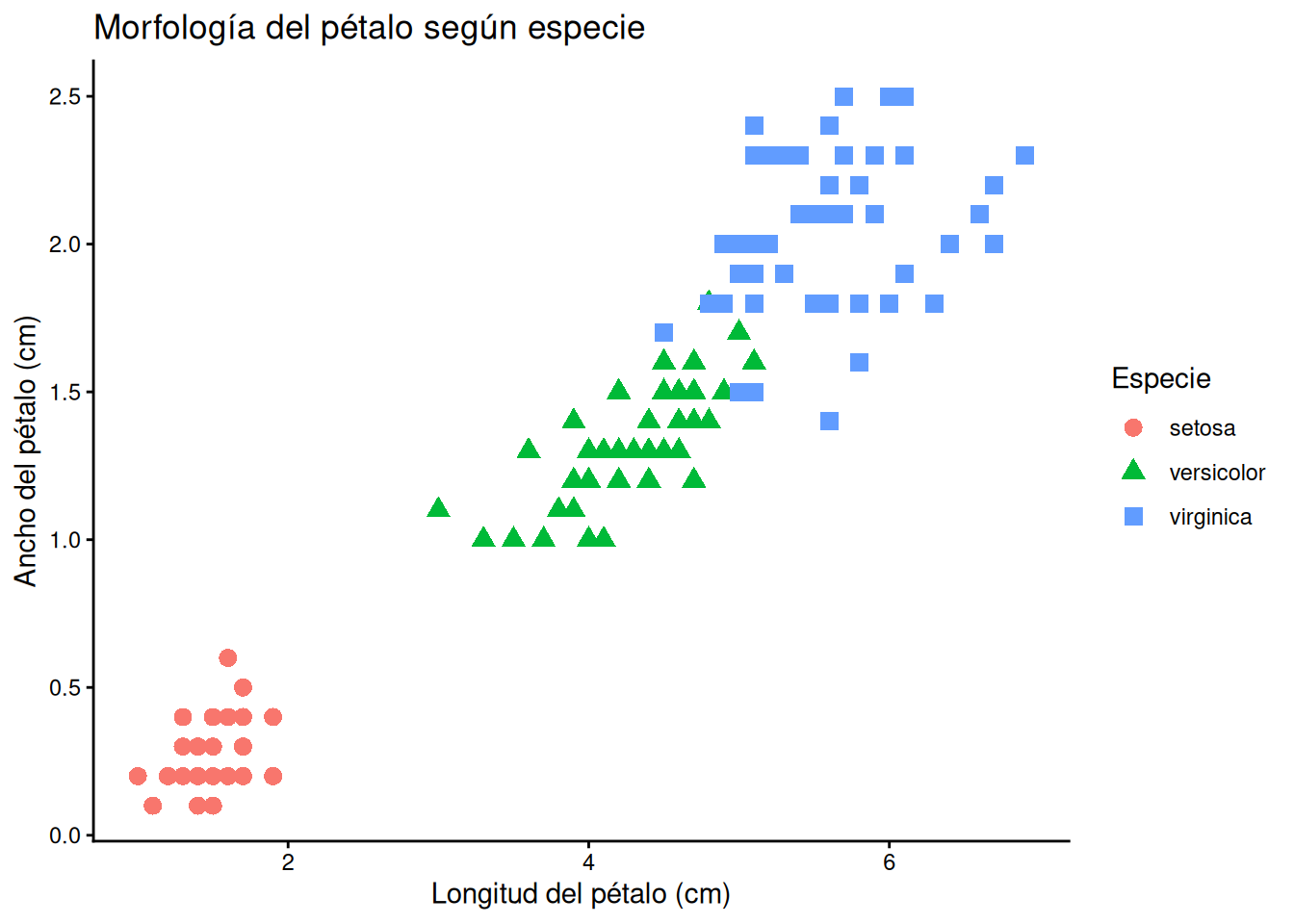
Sitio de interés: En el siguiente enlace encontrarás una lista completa de colores disponibles en R: r-charts.com/es/colores
8.4.4 Gráfico de líneas
Los gráficos de líneas se utilizan para visualizar cómo una variable continua cambia en relación con otra, generalmente vinculada a una serie temporal (horas, días, meses, años, etc.). Para este gráfico utilizaremos el dataset PP_77_22 que contiene datos de precipitación en una localidad de la Provincia de Catamarca correspondiente al período 1977-2022. Para construir este gráfico utilizaremos la función: geom_line()
ggplot(PP_77_22, aes(x = anio, y = precipitacion)) +
geom_line() +
labs(title = "Precipitación anual (1977-2022)",
x = "Año",
y = "Precipitación (mm)") +
theme_classic()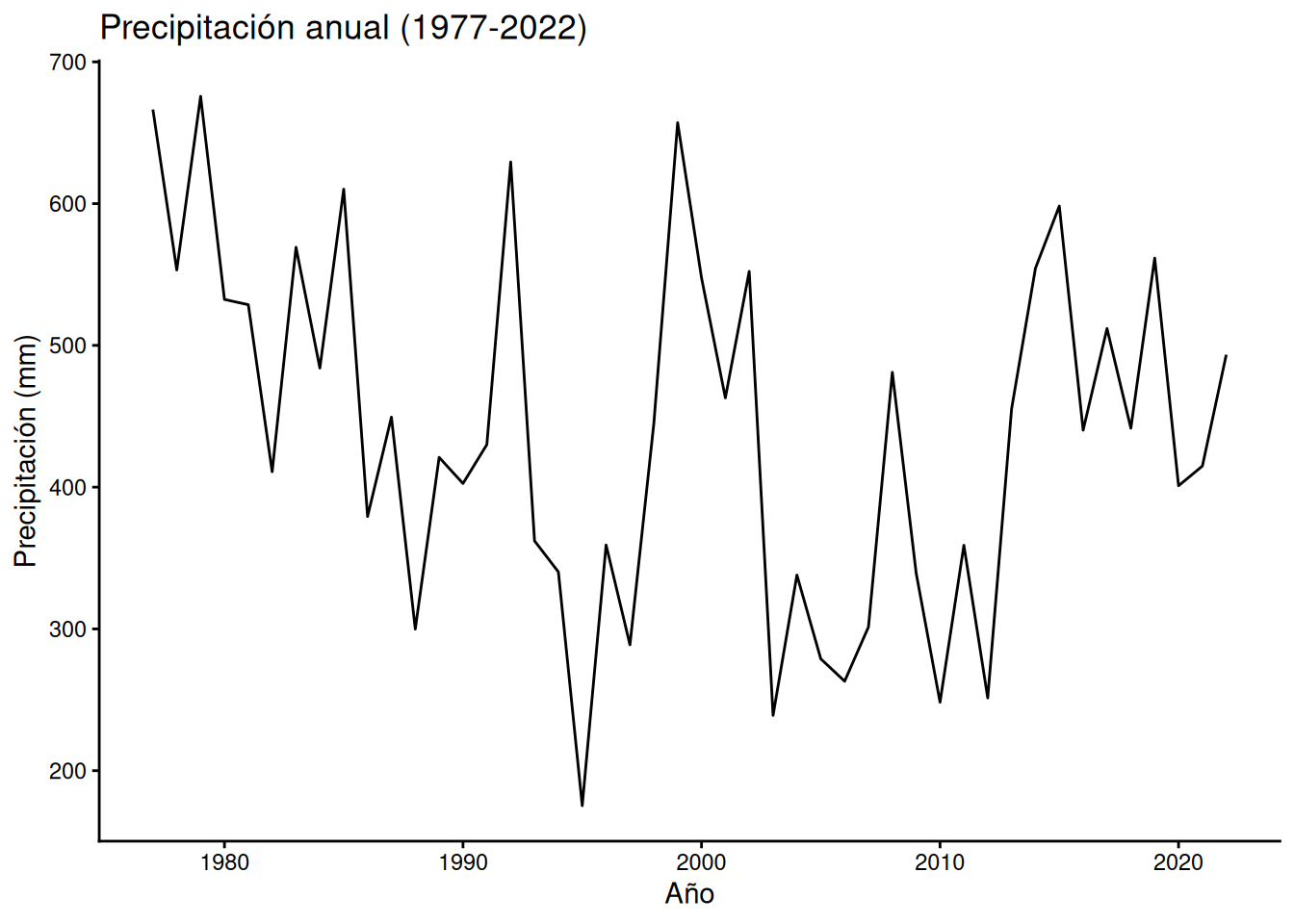
Se puede modificar tanto el tipo como el ancho de las líneas con los argumentos linetype y linewidth.
Tipos de línea: Podemos elegir entre diferentes estilos, como líneas continuas, discontinuas o punteadas, entre otros. (Figura 8.3).
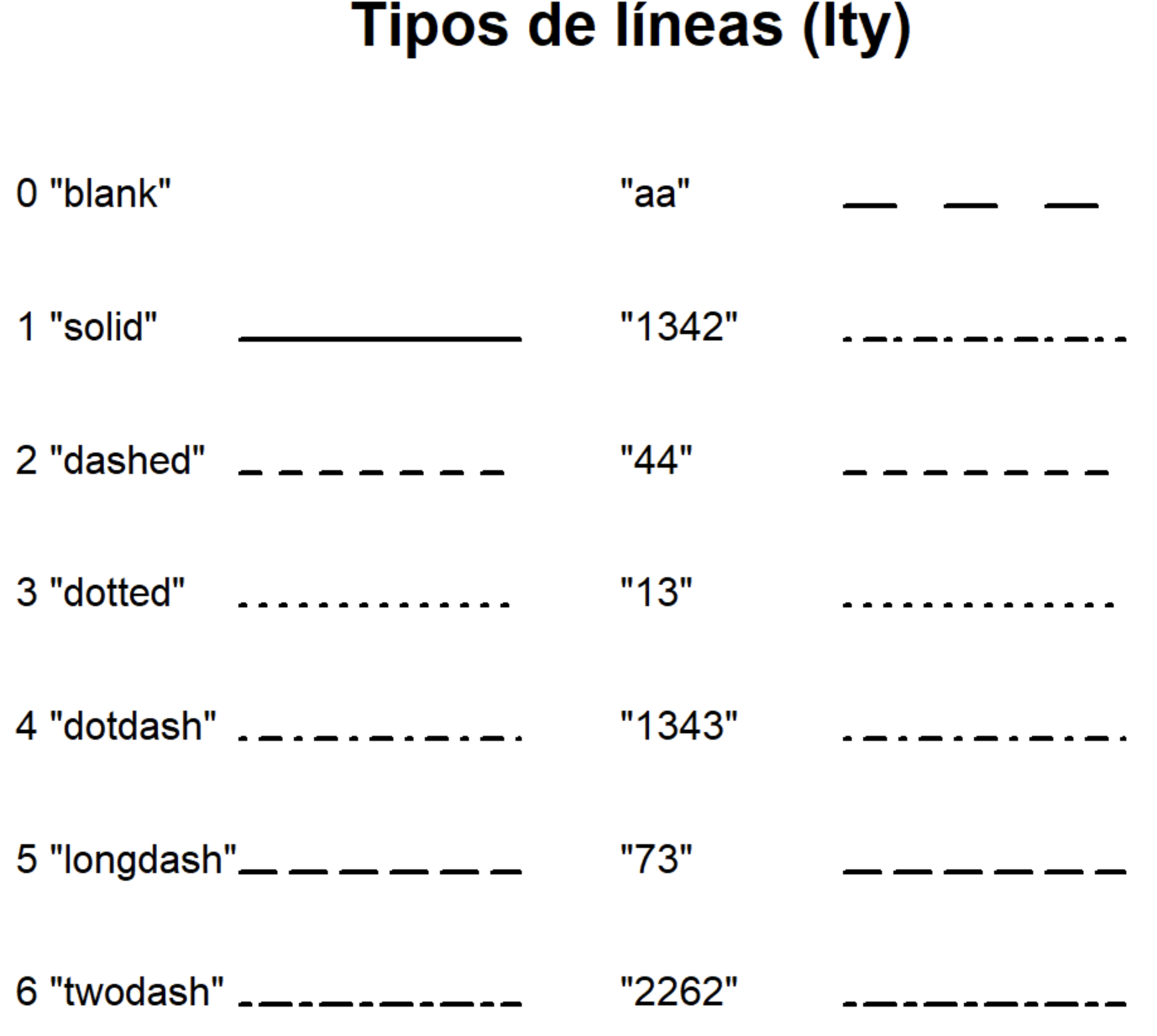
Figura 8.3: Tipos de líneas disponibles mediante linetype.
Espesor de línea: Es posible también ajustar el grosor de la línea para destacar o suavizar su apariencia (Figura 8.4).
Figura 8.4: Espesor de líneas disponibles mediante linetype.
Aplicamos estos argumentos a un ejemplo:
ggplot(PP_77_22, aes(x = anio, y = precipitacion)) +
geom_line(linetype = "dashed", linewidth = 0.8, colour = "#1a5c00") +
labs(title = "Precipitación anual (1977-2022)",
x = "Año",
y = "Precipitación (mm)") +
theme_classic()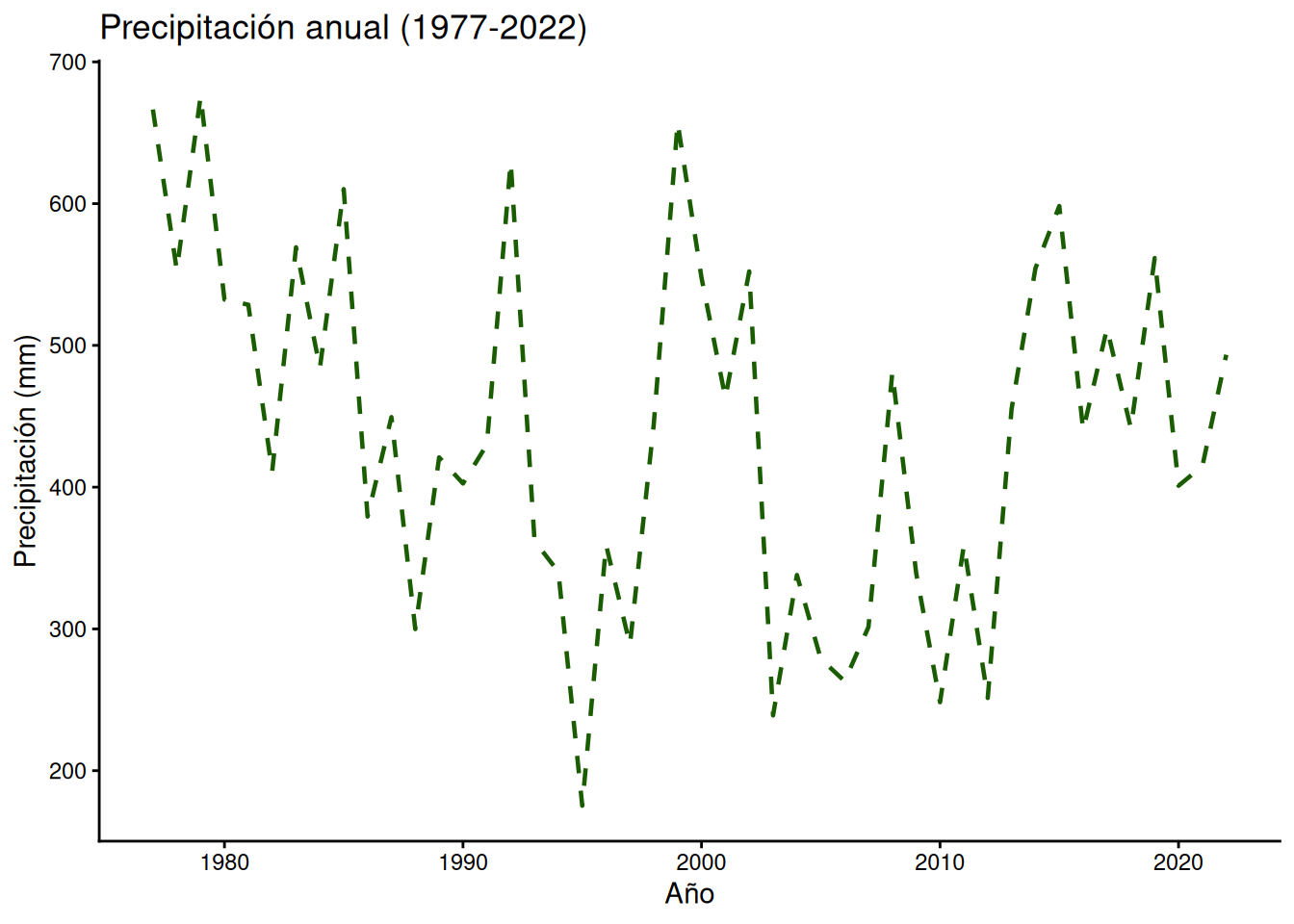
8.4.5 Histograma
Un histograma es un gráfico utilizado para representar la distribución de una variable numérica continua. Este tipo de gráfico divide el conjunto de datos en intervalos (llamados bins o contenedores) y muestra la frecuencia con la que los valores se ubican dentro de cada intervalo. A diferencia del gráfico de barras, en el histograma las barras suelen estar juntas, ya que representan un continuo numérico. Se utilizará la función: geom_histogram().
En el siguiente ejemplo, filtraremos la base MANDARINAS para trabajar únicamente con la variedad “Criolla” y observaremos cómo se distribuye el peso de sus frutos:
# Filtramos la variedad "Criolla" y modificamos color y relleno de los contenedores
MANDARINAS %>%
filter(VARIEDAD == "Criolla") %>%
ggplot(aes(x = PESO)) +
geom_histogram(fill = "#1a5c00", colour = "white") +
labs(title = "Distribución del peso en Mandarina Criolla",
x = "Peso del fruto (g)",
y = "Frecuencia (n)") +
theme_classic()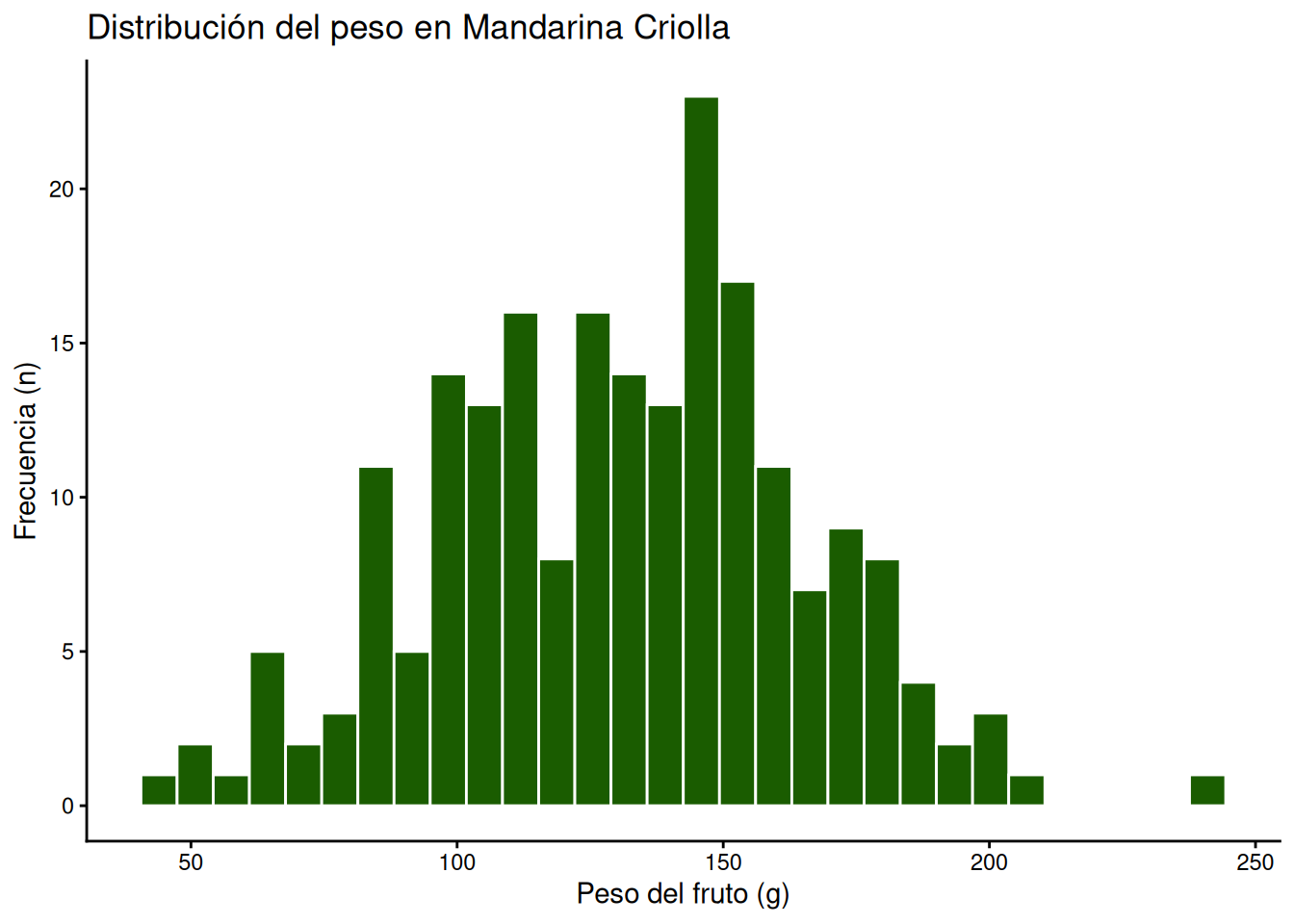
8.5 Ajuste de los contenedores
La apariencia y la capacidad de interpretación de un histograma dependen de cómo definamos los intervalos. Podemos ajustarlos siguiendo dos criterios:
Ajustando el número de intervalos (bins)
A través del argumento bins, especificamos en cuántas barras queremos dividir el total de nuestros datos. Por defecto, R utiliza 30, pero se puede reducir para generalizar la distribución o aumentar para observar mayor detalle.
MANDARINAS %>%
filter(VARIEDAD == "Criolla") %>%
ggplot(aes(x = PESO)) +
geom_histogram(bins = 15, fill = "#1a5c00", colour = "white") +
labs(title = "Histograma con 15 intervalos",
x = "Peso del fruto (g)",
y = "Frecuencia") +
theme_classic()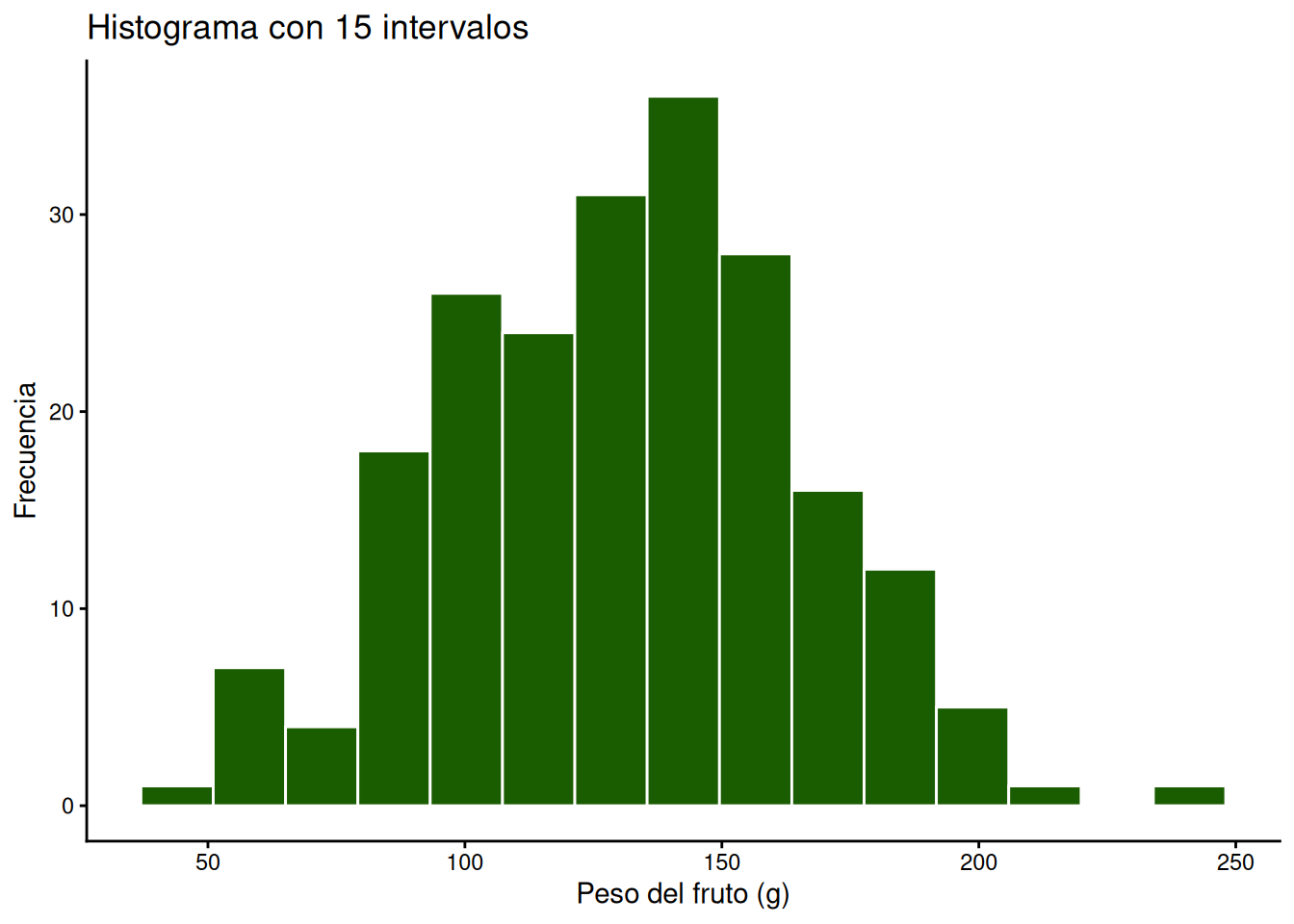
Ajustando el ancho de los contenedores (binwidth)
Con este método, en lugar de decir cuántas barras queremos, definimos el ancho exacto que tendrá cada una en las unidades de nuestra variable (en este caso, gramos). Por ejemplo, si queremos ver cuántos frutos caen en rangos de 20 gramos:
MANDARINAS %>%
filter(VARIEDAD == "Criolla") %>%
ggplot(aes(x = PESO)) +
geom_histogram(binwidth = 20, fill = "#1a5c00", colour = "white") +
labs(title = "Histograma con ancho de intervalo de 20g",
x = "Peso del fruto (g)",
y = "Frecuencia") +
theme_classic()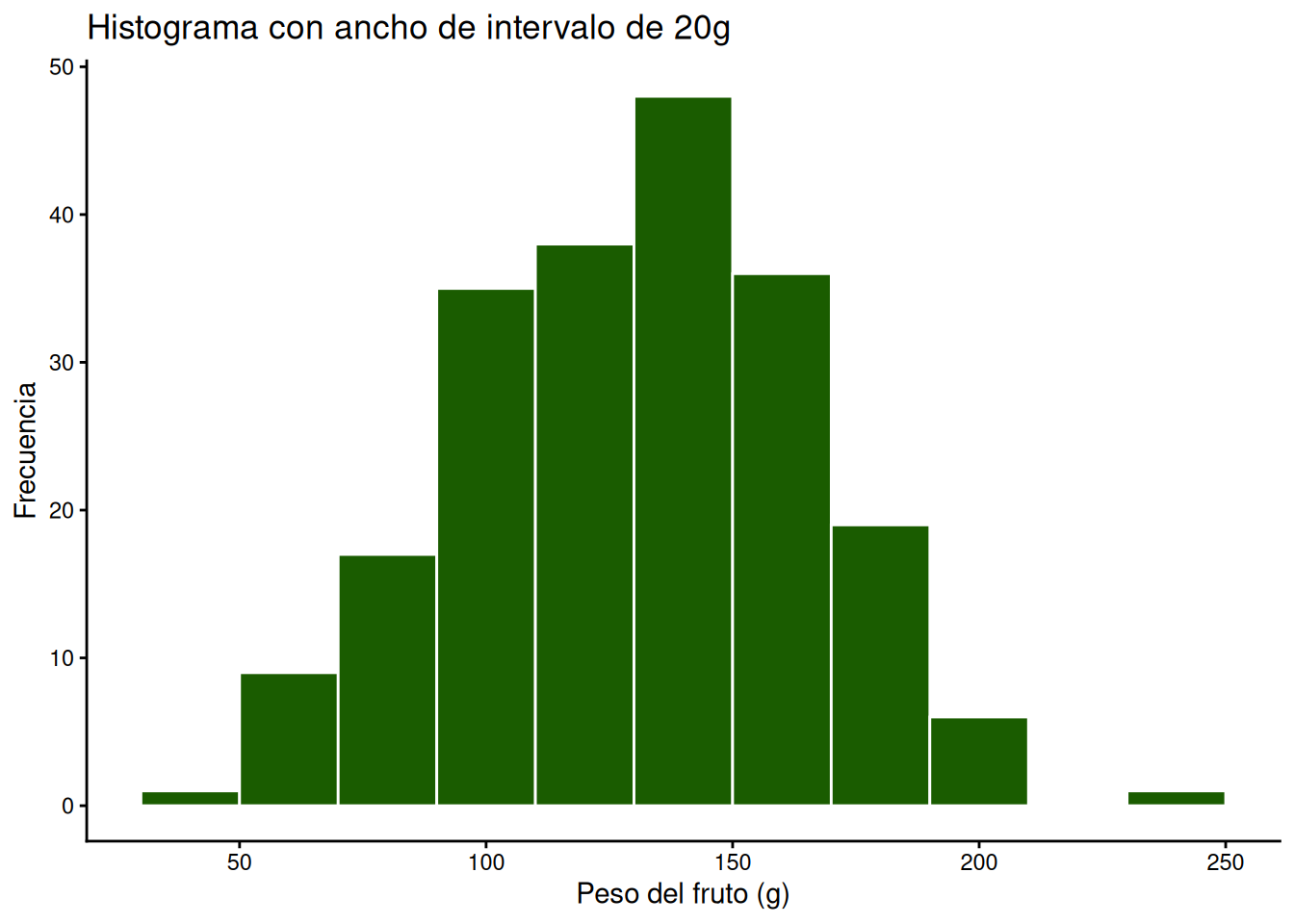
Nota No existe un número ideal de intervalos. Si usamos pocos, perdemos información valiosa; si usamos demasiados, el gráfico podría volverse difícil de leer. Se recomienda probar diferentes valores hasta encontrar el que mejor represente la realidad de los datos analizados.
8.5.1 Polígono de frecuencias
El polígono de frecuencias es una alternativa al histograma que representa la distribución de una variable numérica mediante una línea que conecta los puntos medios (marcas de clase) de los intervalos. Esto permite visualizar la forma general de la distribución de los datos de manera continua.
La principal ventaja de este tipo de representación es que, al no tener barras sólidas, resulta mucho más limpio para superponer y comparar diferentes grupos en un mismo gráfico. Para construirlo, utilizamos la función: geom_freqpoly().
Distribución para una sola variedad
Siguiendo el análisis de la variedad “Criolla”, observaremos cómo la línea suaviza la representación de la distribución del peso que vimos anteriormente en el histograma. Al igual que en el histograma, debemos definir el número de intervalos (bins) o su ancho (binwidth).
# Polígono de frecuencias para una sola variedad
MANDARINAS %>%
filter(VARIEDAD == "Criolla") %>%
ggplot(aes(x = PESO)) +
geom_freqpoly(binwidth = 10, linewidth = 0.8, colour = "#1a5c00") +
labs(title = "Polígono de frecuencias: Peso en Mandarina Criolla",
x = "Peso del fruto (g)",
y = "Frecuencia (n)") +
theme_classic()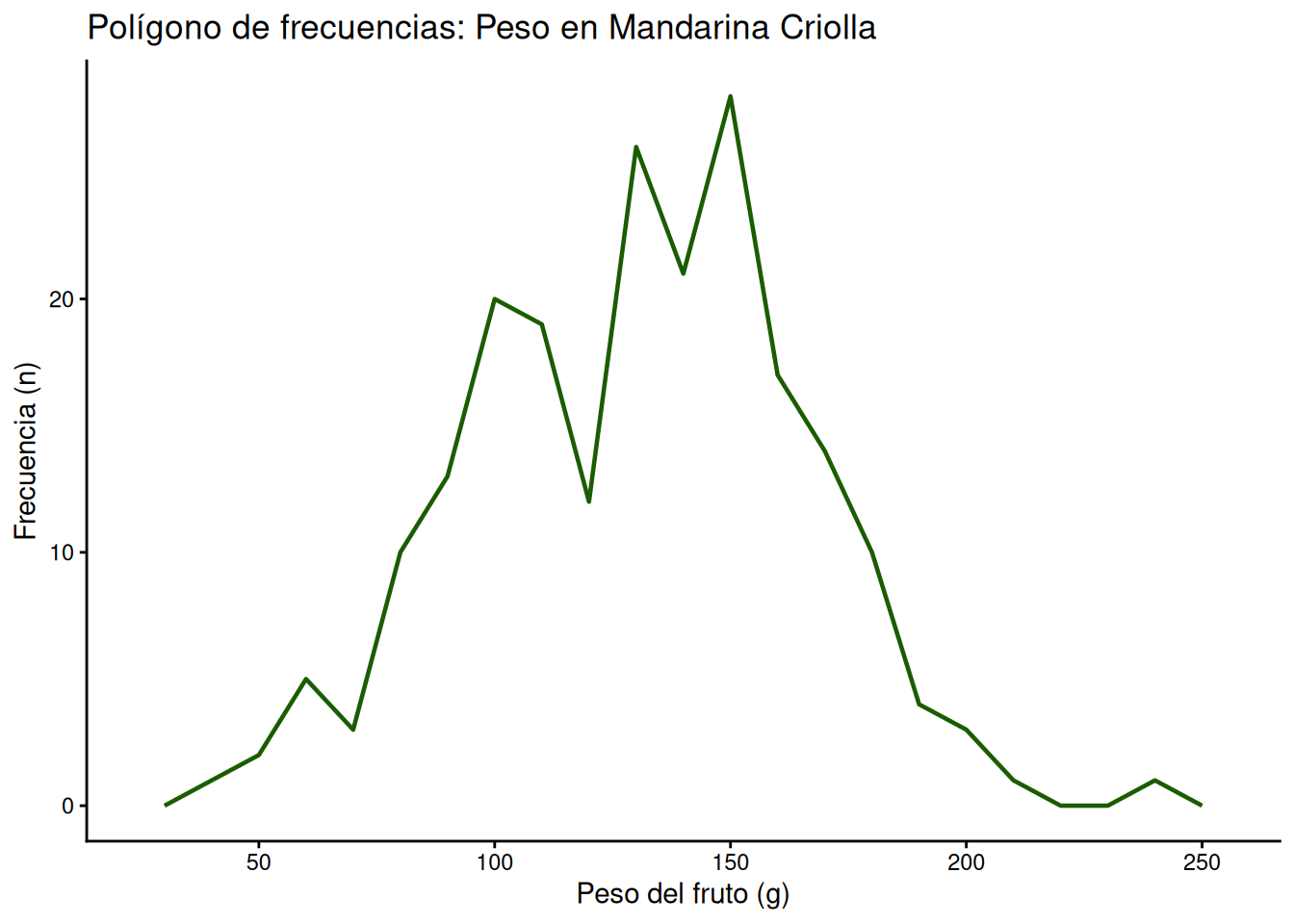
Comparación entre variedades
El verdadero potencial del polígono de frecuencias se expresa cuando queremos comparar grupos. Si intentáramos hacer esto con un histograma, las barras de una variedad superpondrían a las de la otra, impidiendo una visualización clara. Con el polígono, simplemente asignamos la variable VARIEDAD al argumento colour:
# Comparación de perfiles de peso por variedad de mandarina
ggplot(MANDARINAS, aes(x = PESO, colour = VARIEDAD)) +
geom_freqpoly(binwidth = 10, linewidth = 1) +
labs(title = "Comparación de pesos por variedad",
x = "Peso del fruto (g)",
y = "Frecuencia (n)",
colour = "Variedad") +
theme_classic()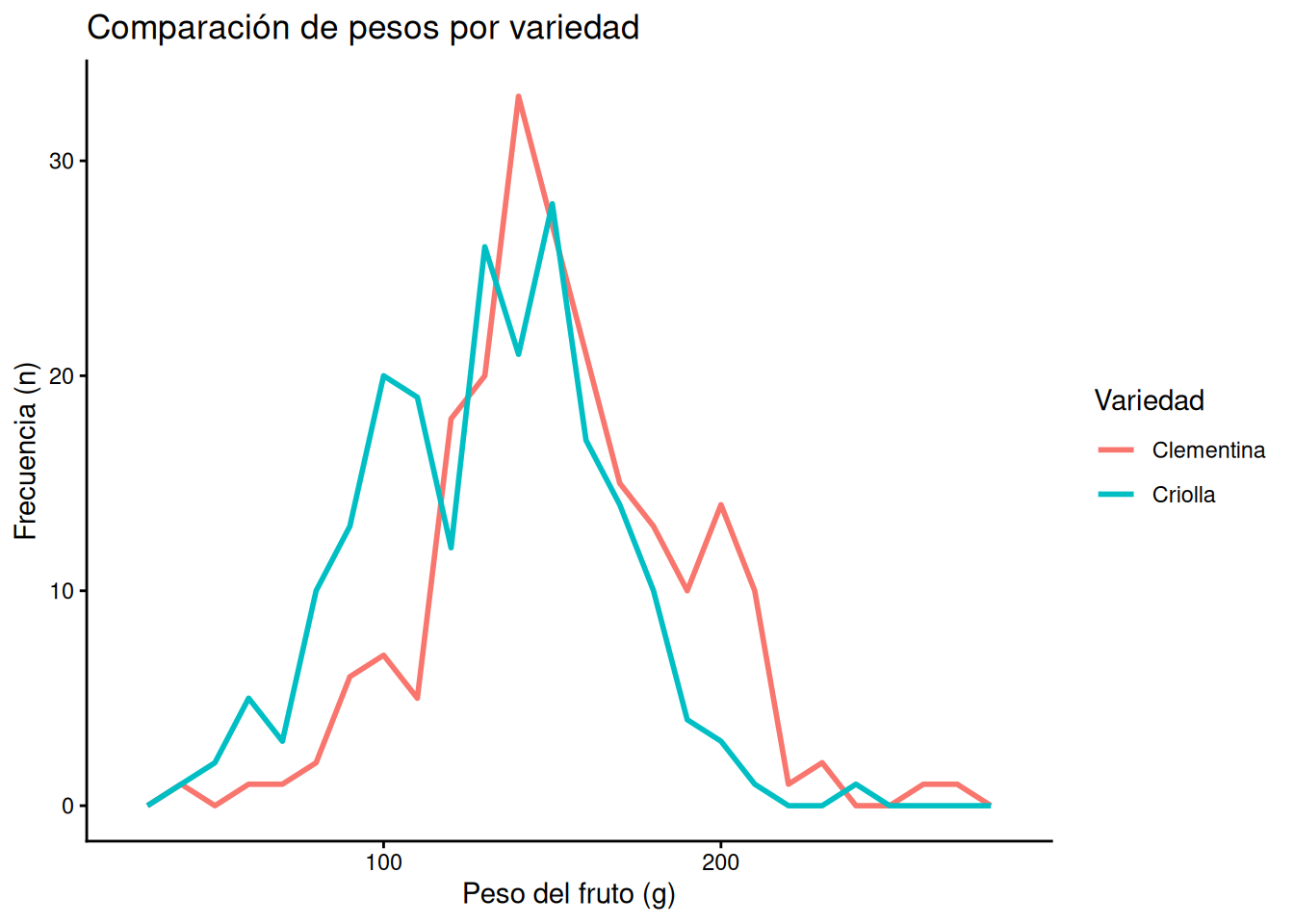
8.5.2 Diagrama de caja y bigotes
El diagrama de cajas y bigotes o boxplot es uno de los gráficos más utilizados para comparar la distribución de una variable numérica entre grupos o tratamientos. Proporcionan una visión de la mediana, los cuartiles, la dispersión y la simetría de los datos, permitiendo además identificar posibles valores atípicos (outliers). Para este gráfico se utilizará la función: geom_boxplot().
En este ejemplo, utilizaremos el set de datos PlantGrowth_es para analizar el peso seco de las plantas según el tratamiento aplicado:
# Boxplot básico con relleno por categoría
ggplot(PlantGrowth_es, aes(x = tratamiento, y = peso, fill = tratamiento)) +
geom_boxplot(alpha = 0.7) +
labs(title = "Distribución del peso seco por tratamiento",
x = "Tratamiento",
y = "Peso seco (g)",
fill = "Tratamiento") +
theme_classic()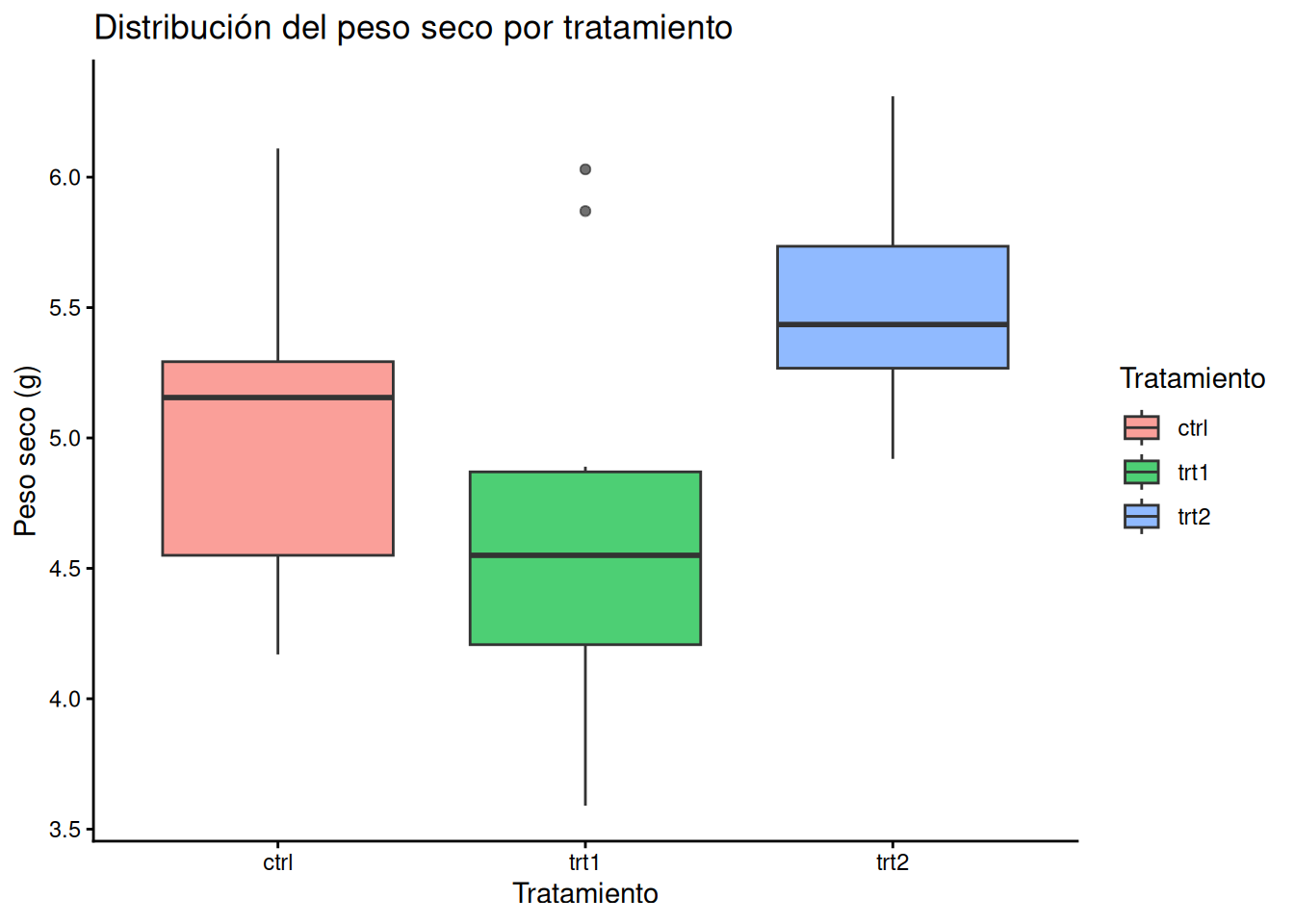
Incorporación de la media aritmética
Por defecto, la línea central del boxplot representa la mediana. Sin embargo, es muy común querer visualizar también la media. Para ello, recurrimos a la función stat_summary():
# Agregamos la media al gráfico
ggplot(PlantGrowth_es, aes(x = tratamiento, y = peso, fill = tratamiento)) +
geom_boxplot(alpha = 0.7) +
stat_summary(fun = mean, geom = "point", color = "black", shape = 18, size = 3) +
labs(title = "Distribución del peso con indicador de media",
x = "Tratamiento",
y = "Peso seco (g)",
fill = "Tratamiento") +
theme_classic()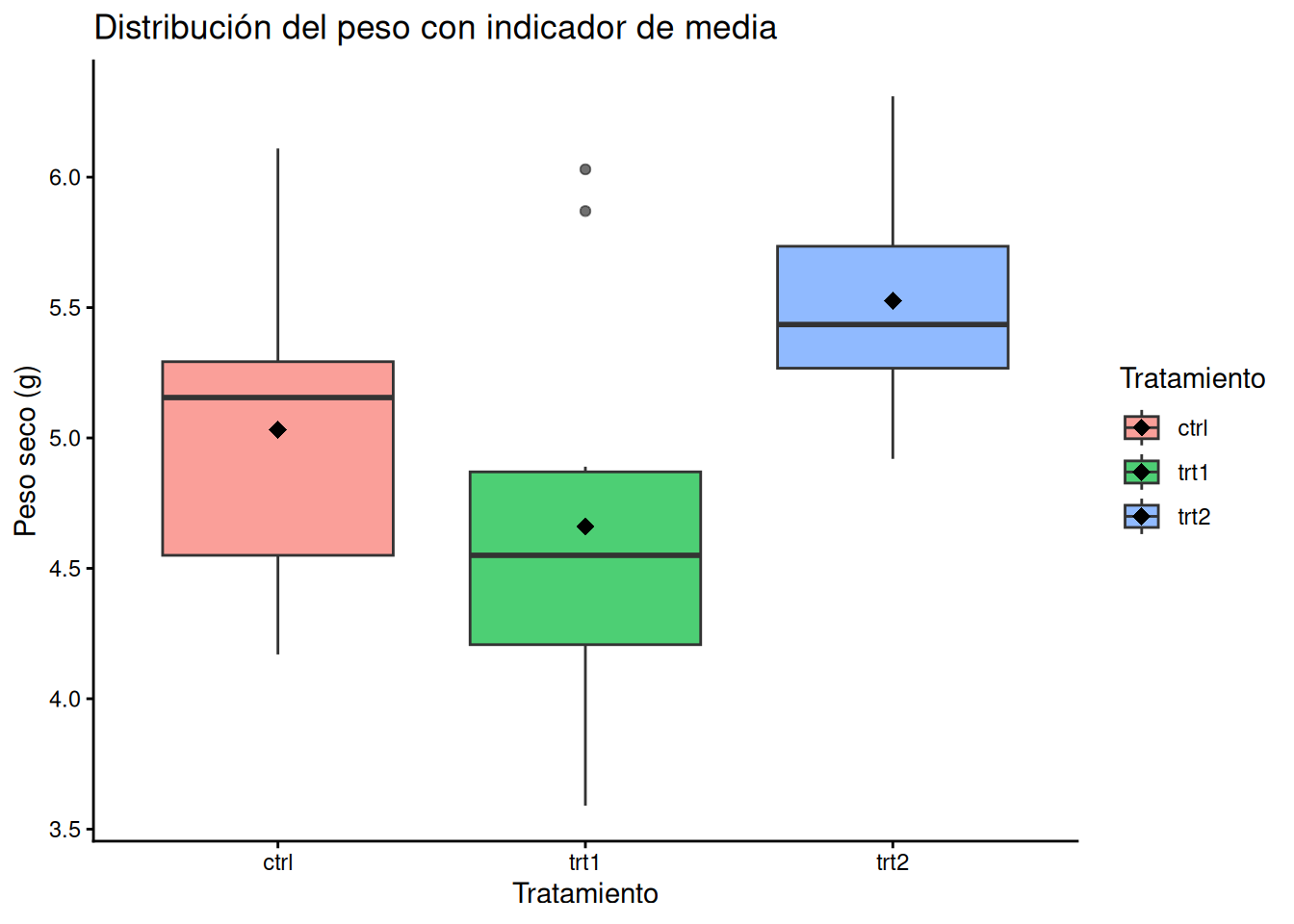
Integración de capas y personalización avanzada
Para un informe técnico o una tesis, se suele combinar varias capas para que el gráfico sea lo más informativo posible. En el siguiente ejemplo, observaremos cómo integrar los datos individuales (jitter), la media, una paleta de colores profesional y una personalización profunda del diseño (theme):
ggplot(PlantGrowth_es, aes(x = tratamiento, y = peso, fill = tratamiento)) +
# 1. Capa de Boxplot: transparencia, ancho de cajas y forma de outliers
geom_boxplot(alpha = 0.6, width = 0.5, color = "black", outlier.shape = 21) +
# 2. Capa de Jitter: muestra los datos individuales evitando superposición
geom_jitter(width = 0.1, alpha = 0.5, size = 2, color = "black") +
# 3. Capa de Media: representada con un diamante amarillo
stat_summary(fun = mean, geom = "point", shape = 23, size = 3, fill = "yellow", color = "black") +
# 4. Estética de colores y etiquetas
scale_fill_brewer(palette = "Set2") +
labs(title = "Análisis comparativo de peso seco",
x = "Tratamientos",
y = "Peso seco (g)",
fill = "Tratamiento") +
# 5. Personalización del tema (diseño visual)
theme_classic() +
theme(
plot.title = element_text(size = 16, face = "bold", hjust = 0.5),
axis.title = element_text(size = 14, face = "bold"),
axis.text = element_text(size = 13, face = "bold"),
axis.ticks.length = unit(0.3, "cm"),
legend.title = element_text(size = 12, face = "bold"),
legend.text = element_text(size = 10),
panel.grid.major.y = element_line(color = "grey90", linewidth = 0.5) # Líneas guía horizontales
) +
# 6. Orientación horizontal para facilitar la lectura
coord_flip()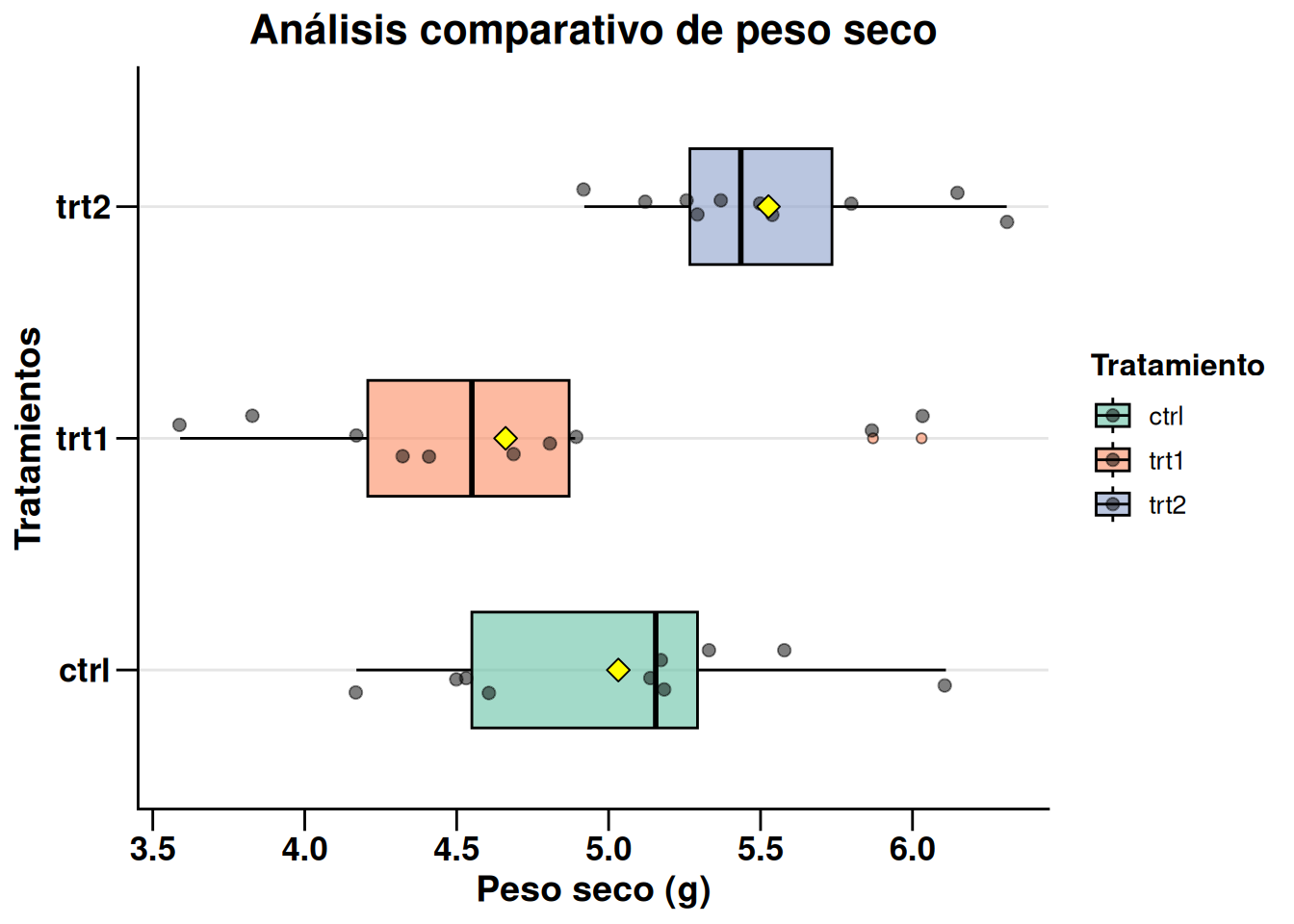
8.6 Bibliografía y sitios de interés
Para ampliar la información, se recomienda consultar: