4 Flujo de trabajo en R
El análisis de datos en RStudio sigue un flujo de trabajo estructurado que permite gestionar, analizar y comunicar resultados de manera eficiente y reproducible. A medida que se avanza en el uso de R, es común encontrar desafíos, especialmente al comenzar a trabajar con estas herramientas. Como se menciona en el libro R para Ciencia de Datos versión en español (2023):
“Es natural frustrarse al comenzar a programar en R, ya que es un lenguaje muy estricto en cuanto a la puntuación: incluso un solo carácter fuera de lugar puede generar un error. Aunque esta sensación de frustración es normal, confía en que es transitoria. Le sucede a todo el mundo y la única forma de superarla es perseverar.”
Wickham & Grolemund (2023)
Desde esta perspectiva, es importante comprender que el progreso en el uso y manejo del software R y su entorno llega con la práctica continua y el conocimiento de sus herramientas.
4.1 ¿Qué es el Tidyverse?

El tidyverse es un conjunto de paquetes de R diseñados para la importación, manipulación, transformación y visualización de datos de manera coherente y eficiente. Entre los paquetes más destacados se encuentran readr para la lectura de archivos de datos, dplyr para manipulación de datos, tidyr para ordenarlos y ggplot2 para visualización de datos, entre otros.
Todos los paquetes que lo componen comparten una filosofía de diseño común, utilizando funciones que son fáciles de aprender y aplicar, además de estar integrados entre sí, lo que permite un flujo de trabajo fluido y uniforme. Su sintaxis intuitiva y coherente reduce la complejidad del código, promoviendo la comprensión y el trabajo colaborativo.
Para la instalación y carga de todos los paquetes que lo componen, deberán realizar las siguientes acciones:
El tidyverse se ha convertido en una de las herramientas más utilizadas en el análisis de datos con R a nivel mundial, precisamente porque sus paquetes acompañan de manera natural cada etapa del flujo de trabajo de manera moderna, eficiente y reproducible.
Importante: Para obtener una lista completa de los paquetes que componen el tidyverse, su instalación y funciones, visite el sitio oficial: tidyverse.org
4.2 Flujo de trabajo
El flujo de trabajo, o workflow, es la secuencia ordenada de pasos que seguimos desde que obtenemos los datos en bruto hasta que comunicamos los resultados de nuestro análisis. En R, este proceso está claramente definido y se compone de seis etapas fundamentales que se ilustran en la Figura 4.1: importar, ordenar, transformar, visualizar, modelar y comunicar. Cada una de estas etapas es de suma importancia en la construcción de un análisis de datos sólido y reproducible.
Recordemos que antes de iniciar el análisis, un paso clave es la instalación y carga de los paquetes que se requerirán en el desarrollo del trabajo. Esto se realiza mediante las funciones de instalación (install.packages("nombre_del_paquete")) y activación (library(nombre_del_paquete)) de los paquetes. Esta acción garantiza que disponemos de los recursos adecuados para cada etapa.
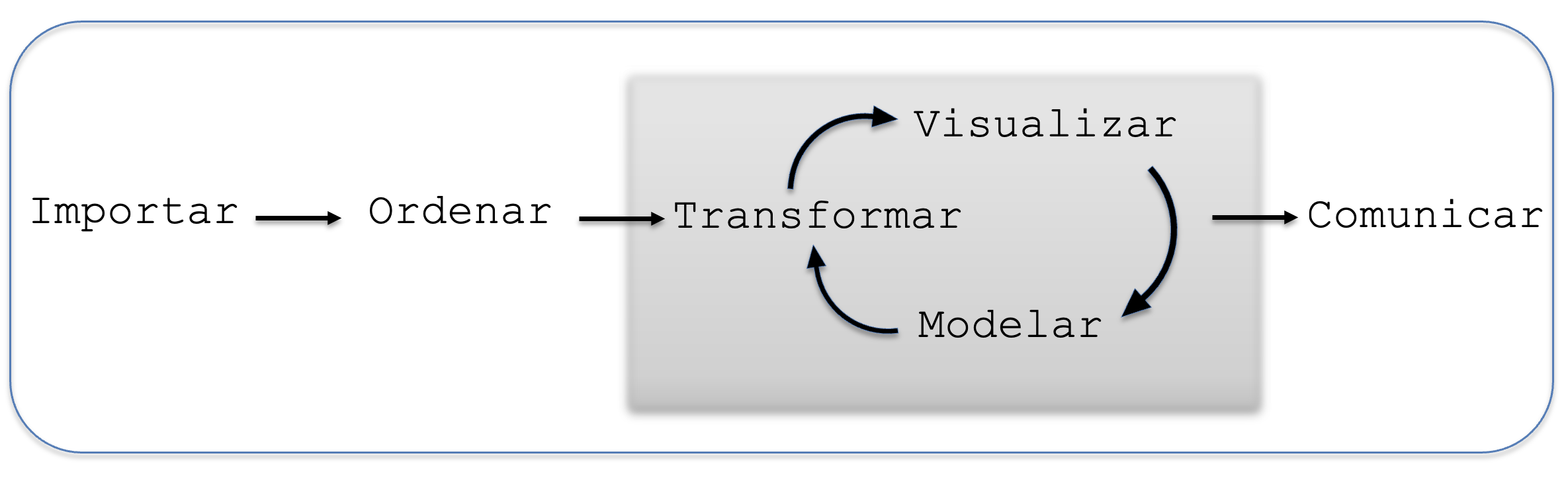
Figura 4.1: Etapas del flujo de trabajo en R.
A lo largo del flujo de trabajo utilizaremos principalmente los paquetes del tidyverse, que cubren la mayoría de las etapas del análisis. Sin embargo, en algunas etapas recurriremos también a paquetes complementarios que nos permitirán ampliar las capacidades de R. En cada capítulo se indicará los paquetes que se utilizarán y cómo cargarlos.
A continuación describiremos cada una de las etapas del flujo de trabajo:
4.2.1 Importar
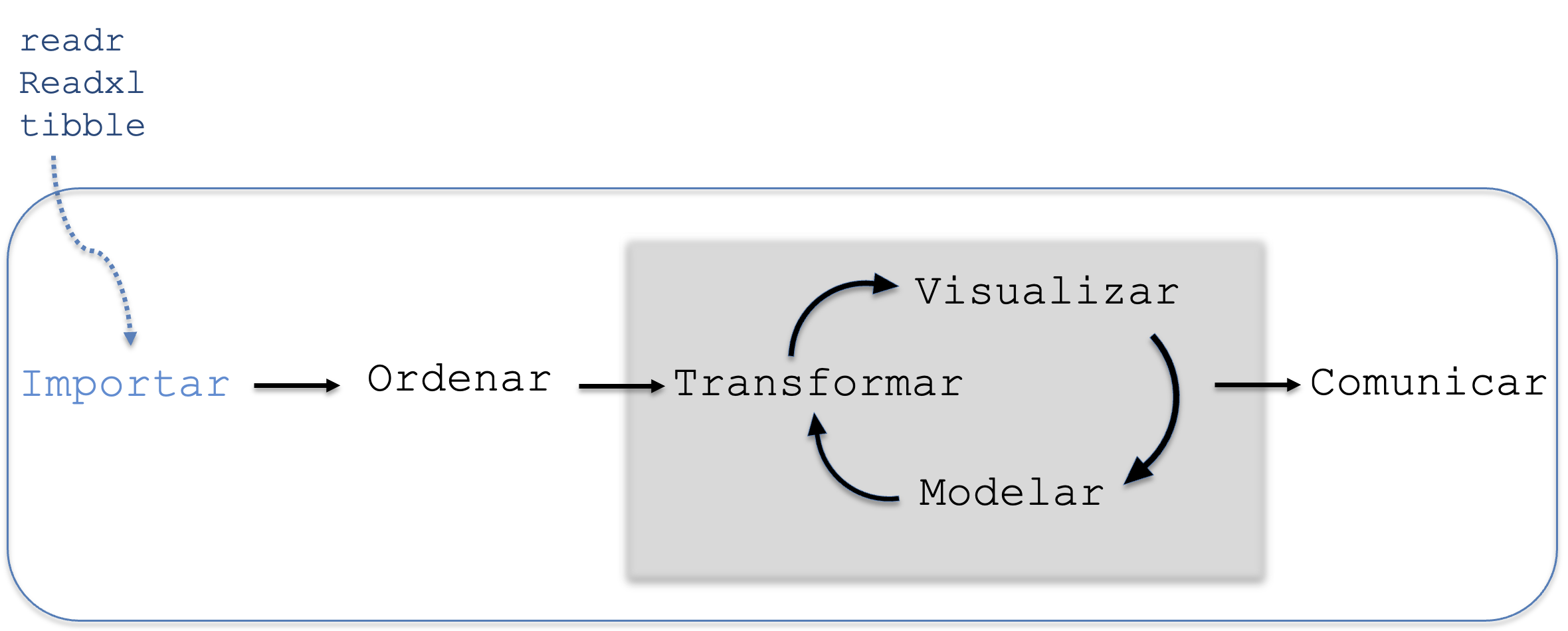
Figura 4.2: Etapa de importación de datos.
El primer paso en cualquier análisis es importar los datos hacia el entorno de RStudio o el proyecto creado en Posit Cloud. Tal como se representa en la Figura 4.2, esto implica cargar datos desde un archivo externo (como .csv o .xlsx) en la memoria de R, donde se podrán manipular y analizar. Asegurar de que los datos se carguen correctamente es fundamental para evitar problemas en etapas posteriores del análisis.
En el Capítulo 5 profundizaremos en las herramientas disponibles para esta etapa.
4.2.2 Ordenar y transformar
Una vez importados los datos, procedemos a ordenarlos. Esto significa estructurarlos de una manera lógica y coherente, siguiendo el principio conocido como tidy data: cada columna representa una variable, cada fila una observación y cada celda debe contener un único valor. Esta estructura, graficada en la Figura 4.3, facilita el uso de funciones consistentes.
Mantener los datos en este formato ordenado facilita el uso de funciones y paquetes en R que requieren consistencia estructural para operar correctamente. Para tareas más específicas de limpieza de datos, como el manejo de nombres de columnas o valores faltantes, existen paquetes complementarios como janitor y naniar, cuyas funciones principales se exponen en el capítulo 6.
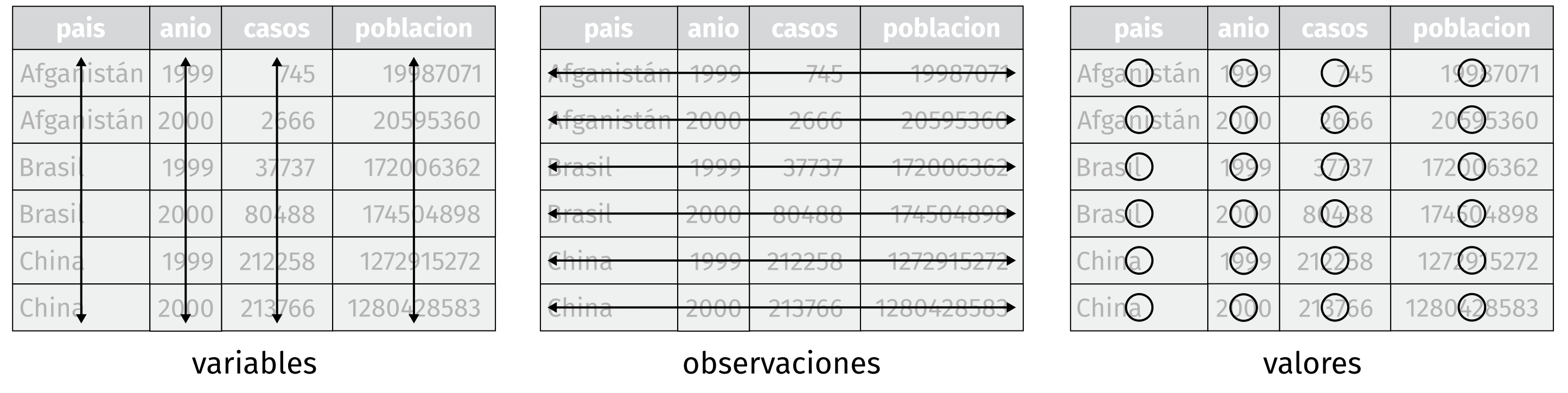
Figura 4.3: Representación de la estructura de datos ordenados (tidy data).
El siguiente paso es transformar los datos. Como se observa en la Figura 4.4, la transformación puede incluir filtrar observaciones relevantes, crear nuevas variables derivadas de las existentes, o realizar cálculos agregados como promedios. Este proceso es parte del llamado data wrangling, que asegura que los datos se encuentren en una forma que permita realizar análisis y visualizaciones de manera eficaz.
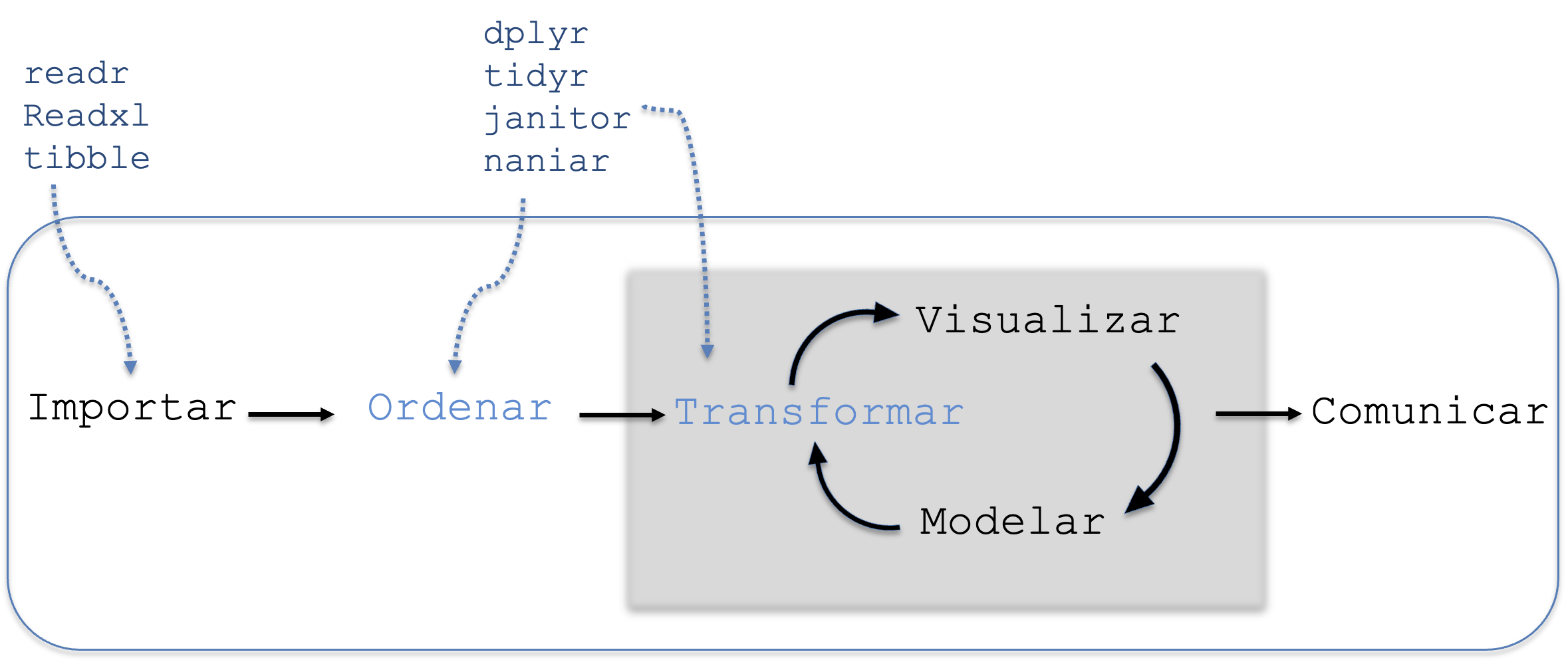
Figura 4.4: Etapa de transformación de datos.
En el Capítulo 6 profundizaremos en las herramientas disponibles para esta etapa.
4.2.3 Visualizar
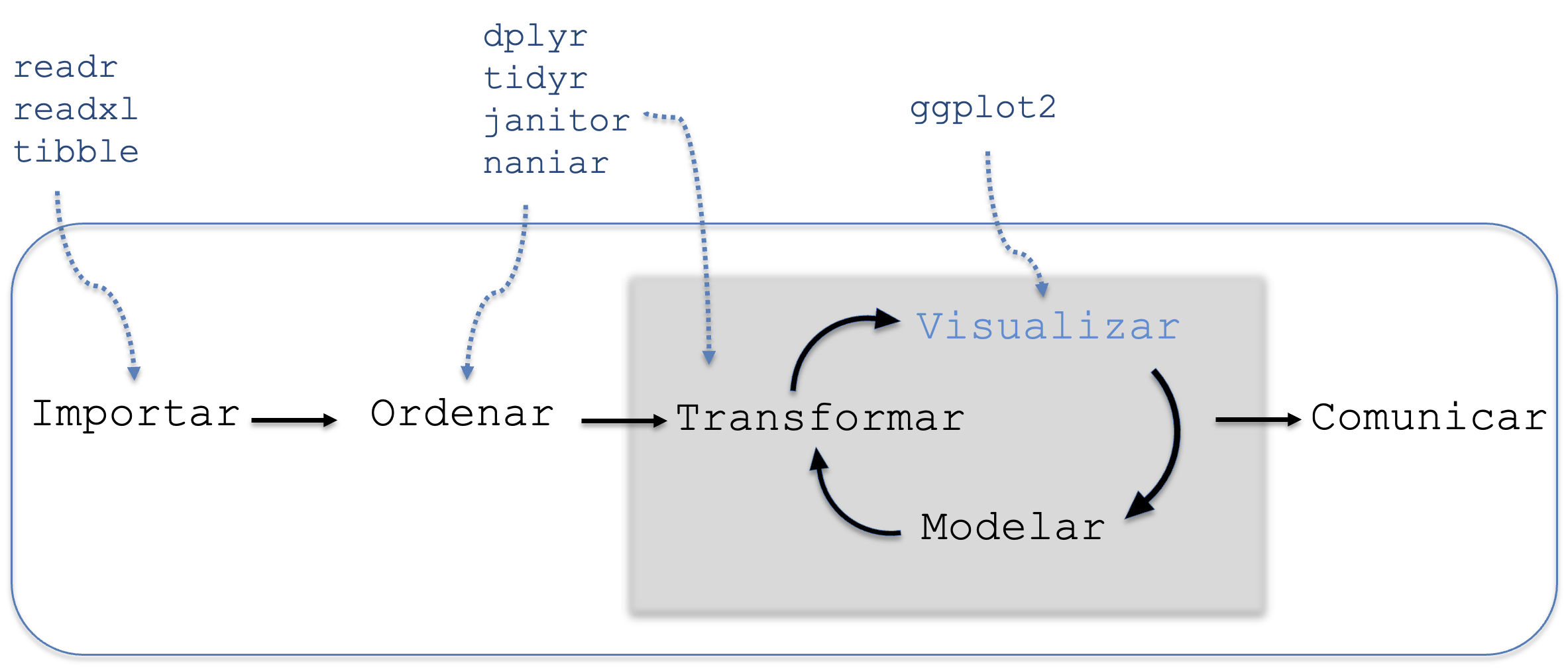
Figura 4.5: Etapa de visualización de datos.
Después de ordenar y transformar los datos, el siguiente paso es visualizarlos, representado en la Figura 4.5. Para esta etapa contamos principalmente con el paquete ggplot2, aunque existen muchos otros paquetes disponibles en R para la visualización de datos. La visualización permite detectar patrones, identificar tendencias y descubrir relaciones que no serían evidentes solo a través de tablas de frecuencias o medidas de resumen. Una visualización bien diseñada puede generar nuevas preguntas y dirigir el análisis hacia aspectos que no se habían considerado inicialmente.
En los Capítulos 7 y 8 profundizaremos en las herramientas disponibles para esta etapa.
4.2.4 Modelar
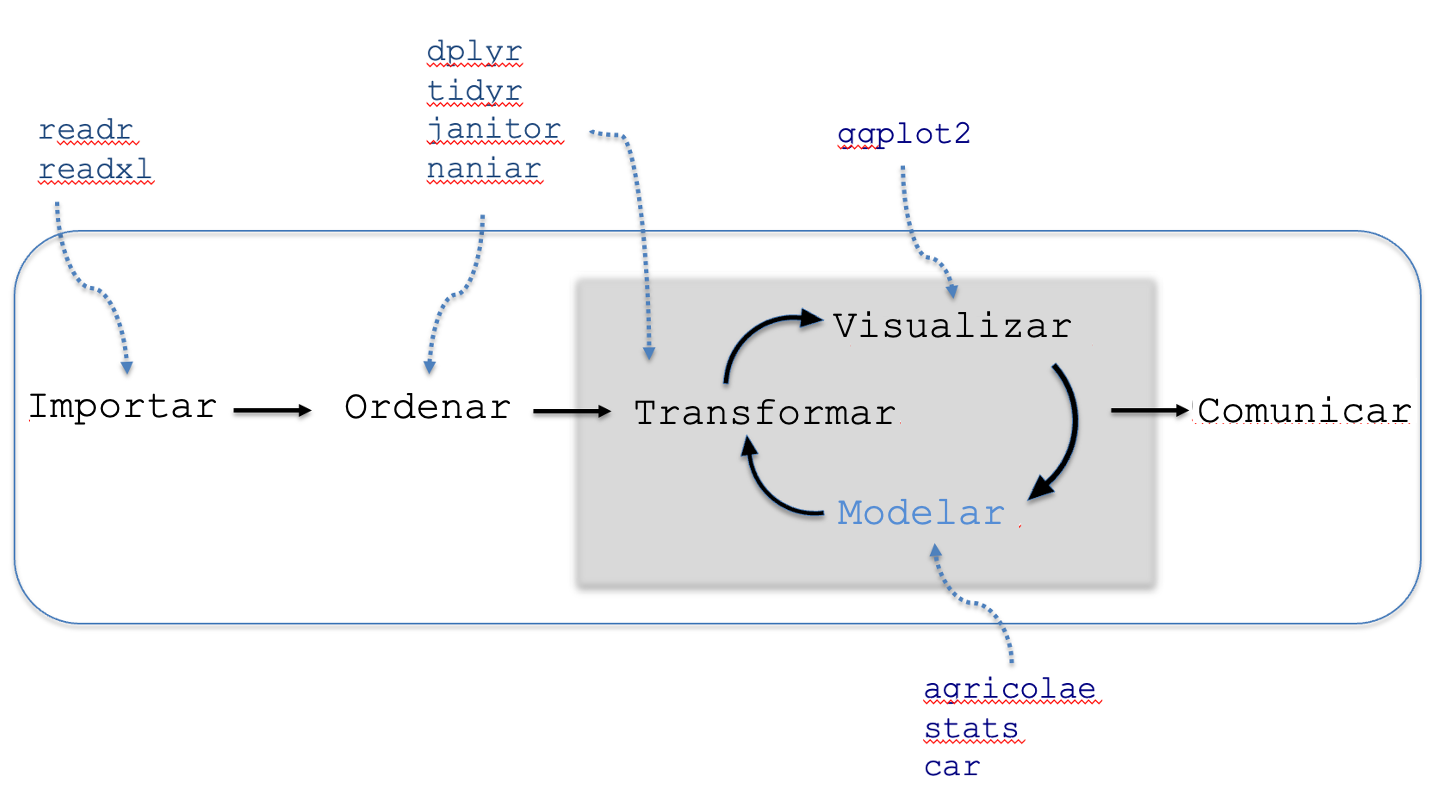
Figura 4.6: Etapa de modelización de datos.
La modelización, ilustrada en la Figura 4.6, es la etapa donde el análisis cobra mayor profundidad: a partir de los patrones identificados en la visualización, los modelos estadísticos nos permiten responder preguntas concretas y cuantificar con precisión las relaciones entre las variables. Para esta etapa, R cuenta con funciones de R base como lm() para modelos de regresión lineal y aov() para análisis de varianza (ANOVA), además de paquetes especializados como agricolae, diseñado específicamente para el análisis de experimentos agropecuarios.
La modelización y la visualización son procesos complementarios; en la práctica, el análisis suele moverse de forma iterativa entre ambos, refinando modelos y ajustando visualizaciones conforme se profundiza en el entendimiento de los datos.
Una de las grandes fortalezas de R en esta etapa es la enorme diversidad de paquetes especializados disponibles para distintas disciplinas. Desde la ecología y la epidemiología hasta el análisis espacial o la economía agraria, existe una amplia comunidad de desarrolladores que contribuye con herramientas específicas para cada campo, haciendo de R una plataforma especialmente poderosa para investigadores de diversas áreas.
Si bien el modelado estadístico excede el alcance de este libro, un buen lugar para empezar a explorar los paquetes disponibles es el repositorio oficial de R: paquetes de CRAN.
4.2.5 Comunicar
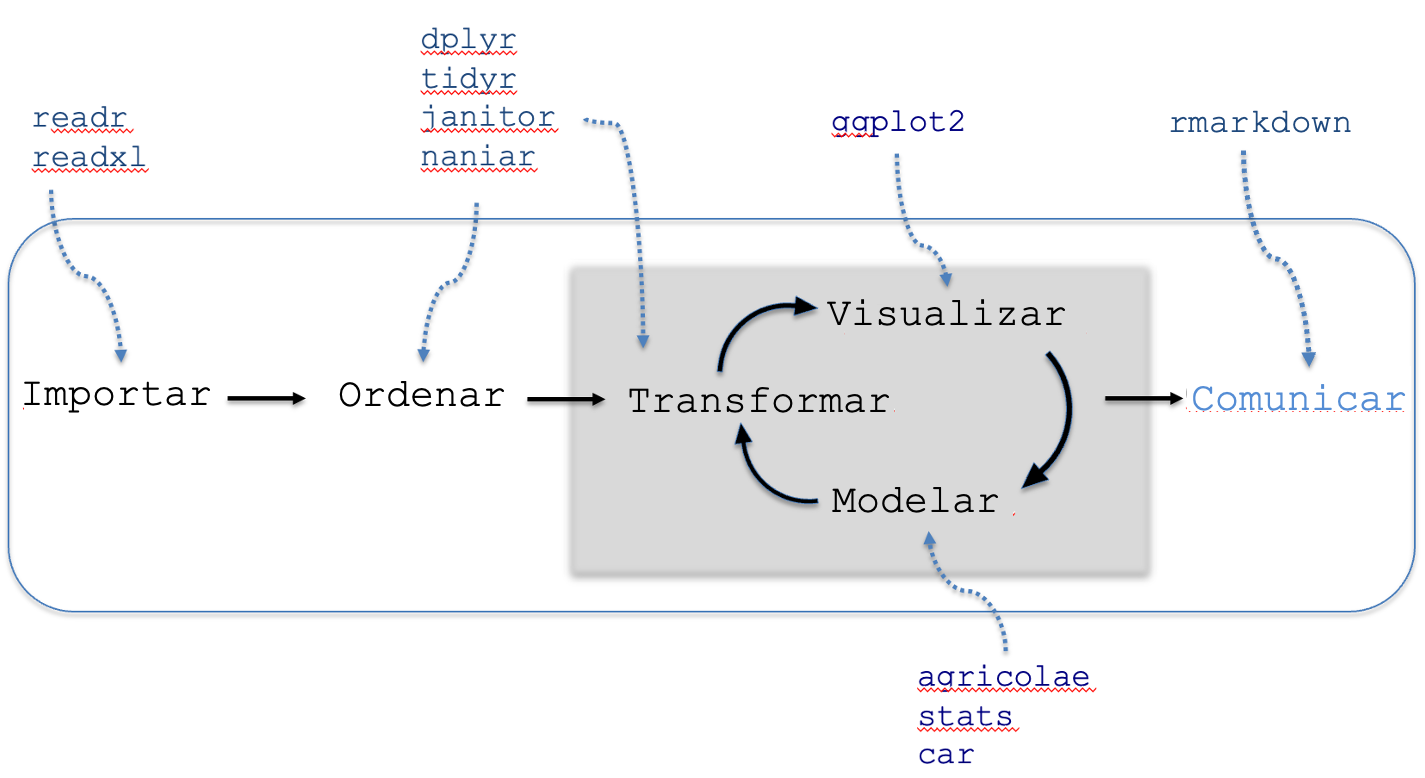
Figura 4.7: Etapa de comunicación de resultados.
Comunicar los resultados es el último paso del flujo de trabajo, como se muestra en la Figura 4.7. Esta etapa es esencial para que el trabajo realizado trascienda el entorno de R y cierra el ciclo del análisis, permitiendo que el conocimiento generado sea compartido, evaluado y aplicado tanto en la toma de decisiones como en el marco de las investigaciones científicas. El paquete rmarkdown es una herramienta excelente para este propósito, ya que permite combinar código, texto y visualizaciones en un único documento, facilitando la creación de informes reproducibles y dinámicos.
La comunicación no se limita a mostrar gráficos o tablas; implica también una narración clara que contextualice los resultados y explique su relevancia. En este sentido, la capacidad de presentar adecuadamente los hallazgos es tan importante como el análisis mismo.
En el capítulo 9 profundizaremos en las herramientas disponibles para esta etapa.
4.3 Bibliografía y sitios de interés
Para ampliar la información, se recomienda consultar: