7 Visualización I: Fundamentos
La visualización de datos constituye otra etapa fundamental dentro del flujo de trabajo de cualquier análisis estadístico en R. Es la instancia en la que los datos procesados se transforman en representaciones gráficas, facilitando su exploración, interpretación y comunicación.
Como hemos visto en el capítulo anterior, una adecuada manipulación de los datos es el paso previo necesario para construir visualizaciones significativas. Tal como se destaca en la Figura 7.1, la visualización no solo permite presentar resultados, sino también profundizar en el análisis, facilitando la identificación de patrones, tendencias y valores atípicos.
Existen numerosos paquetes en R para la generación de gráficos, pero en este libro utilizaremos ggplot2, que forma parte del tidyverse. Este enfoque permite construir visualizaciones de manera estructurada mediante la combinación de distintos componentes.
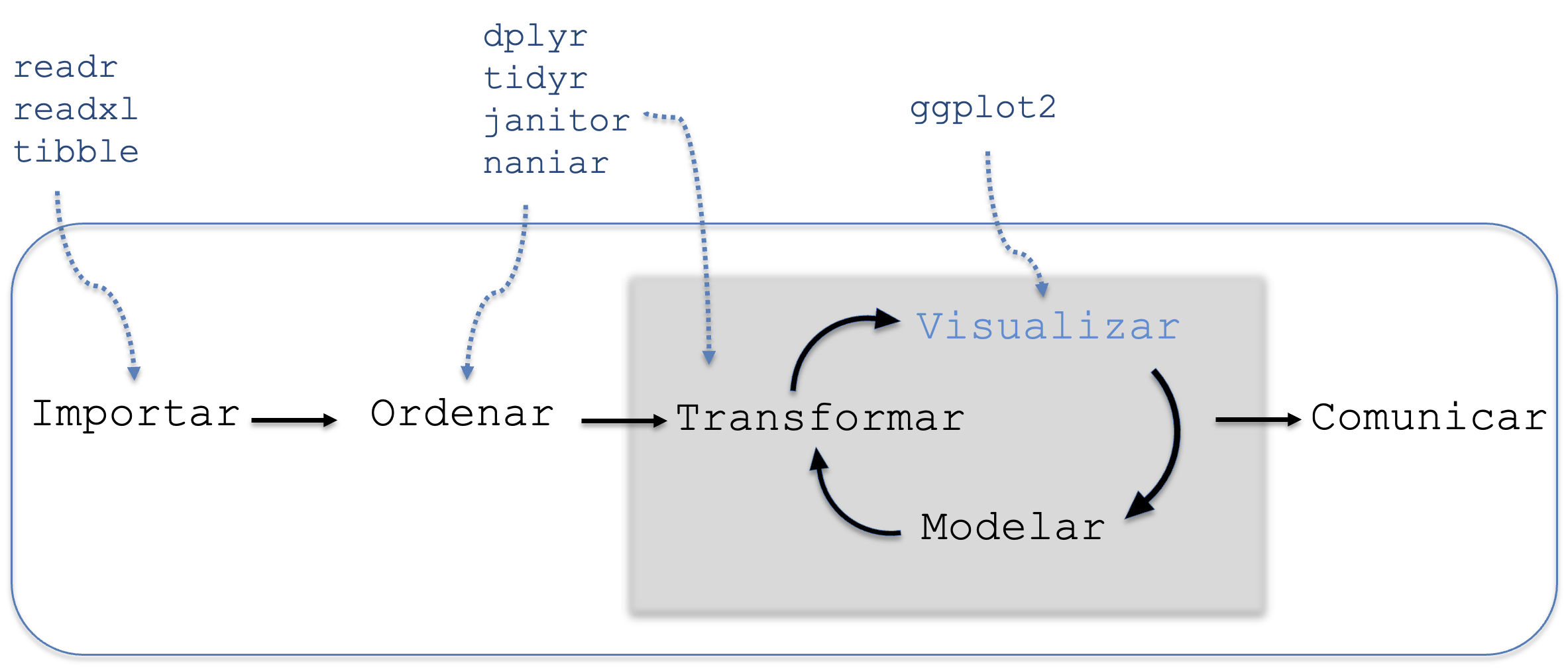
Figura 7.1: Etapa de visualización de datos.
7.1 Cargamos los paquetes
En este paso debemos cargar todos los paquetes que utilizaremos para el análisis de los datos. Cargaremos el tidyverse, que incluye a ggplot2 en su entorno y el paquete readxl que ya hemos estudiado en capítulos anteriores y nos permitirá trabajar con nuestras bases de datos externas.
7.2 Las bases de datos
Continuaremos trabajando con las bases MANDARINAS y PlantGrowth. Al igual que hicimos en secciones anteriores, cargaremos el archivo de Excel externo y prepararemos el dataset interno de R renombrando sus variables al español:
# Cargamos la base de datos MANDARINAS
MANDARINAS <- read_excel("datos/mandarinas.xlsx")
# Creamos el objeto
PlantGrowth_es <- PlantGrowth %>%
rename(peso = weight,
tratamiento = group)
# Observamos las primeras filas de "PlantGrowth_es" para verificar la estructura
head(PlantGrowth_es)## peso tratamiento
## 1 4.17 ctrl
## 2 5.58 ctrl
## 3 5.18 ctrl
## 4 6.11 ctrl
## 5 4.50 ctrl
## 6 4.61 ctrl7.3 El paquete ggplot2
![]()
ggplot2 es un paquete de R ampliamente utilizado para la creación de gráficos estadísticos. Está diseñado bajo la filosofía de la “gramática de los gráficos” (grammar of graphics), propuesta por Leland Wilkinson. Su enfoque permite construir gráficos de manera modular, a partir de la combinación de distintos componentes, conocidos como capas.
Esta estructura lo convierte en una herramienta sumamente versátil, capaz de generar desde gráficos exploratorios rápidos hasta figuras complejas de alta calidad, listas para ser incluidas en publicaciones científicas, informes técnicos o presentaciones académicas.
7.4 Capas
Los gráficos elaborados con este paquete se construyen de manera modular a través de capas, tal como se presenta en la Figura 7.2. El proceso se inicia definiendo los datos y la estética, es decir, las variables que se asignarán a los ejes y otras propiedades visuales como el color o el tamaño. Posteriormente, se añaden las geometrías (geoms), que determinan el tipo de gráfico, como puntos (geom_point), líneas (geom_line) o barras (geom_bar).
A partir de esta estructura básica, es posible añadir capas adicionales para configurar escalas, ejes, facetas y temas, lo que permite ajustar elementos como leyendas, rótulos y el estilo general del gráfico.
Figura 7.2: Capas que componen la gramática de gráficos en ggplot2.
Para comprender la gramática para la creación de gráficos, es necesario identificar sus capas principales:
Datos (
data): el conjunto de datos que se desea visualizar.Estética (
aes()): define cómo las variables se mapean a propiedades visuales (ejes, color, tamaño, etc.).Geometrías (
geoms): determinan el tipo de gráfico que se construye.Facetas (
facet_wrap()/facet_grid()): permiten dividir el gráfico en múltiples paneles según una o más variables.Coordenadas (
coord): definen el sistema de ejes y su transformación.Tema (
theme): controla el aspecto visual general (tipografías, colores, márgenes, cuadrículas, entre otros).
A continuación exploraremos cada una de estas capas.
7.4.1 El lienzo
El primer paso para construir un gráfico es crear un lienzo vacío. Esta será la base estructural sobre la cual se irán agregando las capas sucesivas. Para ello recurrimos a la función ggplot():

7.4.2 La estética (aes)
La función aes() define cómo las variables del set de datos se asignan a los atributos visuales del gráfico. Es decir, establece el mapeo entre variables y propiedades visuales.
Los argumentos más utilizados son:
x: posición en el eje horizontal (abscisas).y: posición en el eje vertical (ordenadas).colour: color del contorno de las formas o de las líneas y puntos.fill: color de relleno interno de figuras sólidas, como barras o cajas.size: tamaño de los elementos geométricos como puntos o líneas.alpha: nivel de transparencia de los elementos. Valores cercanos a1indican mayor opacidad y los cercanos a0, mayor transparencia.shape: forma geométrica de los puntos (círculos, triángulos, cruces, etc).
# Asignamos los datos al lienzo e indicamos qué variable corresponde a cada eje
ggplot(PlantGrowth_es, aes(x = tratamiento, y = peso))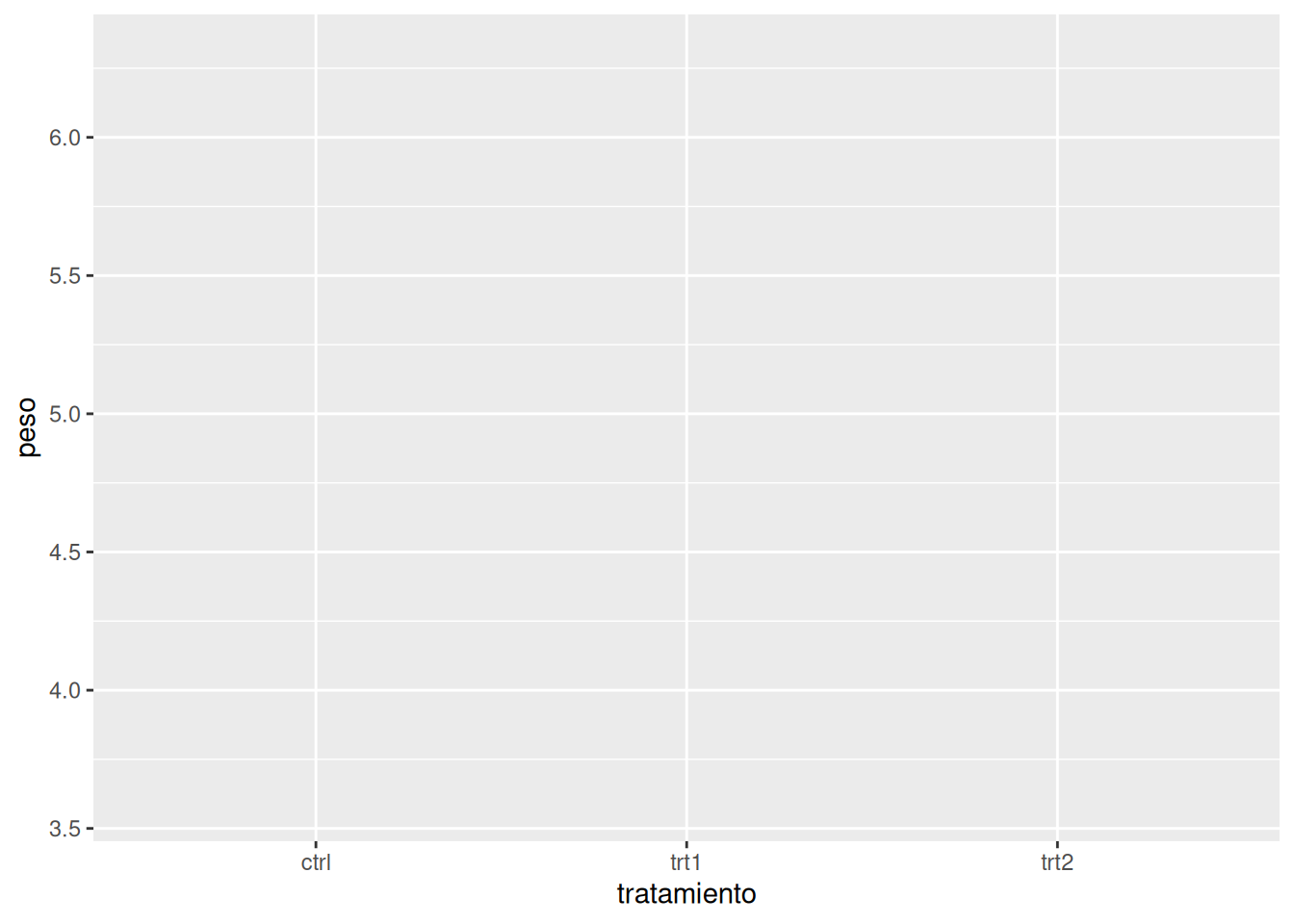
En este punto, aún no se visualiza un gráfico, ya que falta especificar la geometría que determinará el tipo de representación.
7.4.3 La geometría (geoms)
Las geometrías indican el tipo de gráfico que se desea construir. Su elección depende de la naturaleza de las variables (cualitativas o cuantitativas) y del objetivo del análisis. Algunas de las más utilizadas son:
geom_point()— gráfico de puntos o dispersión.geom_boxplot()— diagrama de caja y bigotes o boxplot.geom_col()— gráfico de barras con valores reales.geom_bar()— gráfico de barras con conteos.geom_histogram()— histograma.geom_line()— gráfico de líneas.
7.4.4 Uso de geometrías básicas
A continuación se presentan algunos ejemplos aplicados al dataset PlantGrowth_es.
Gráfico de puntos geom_point()
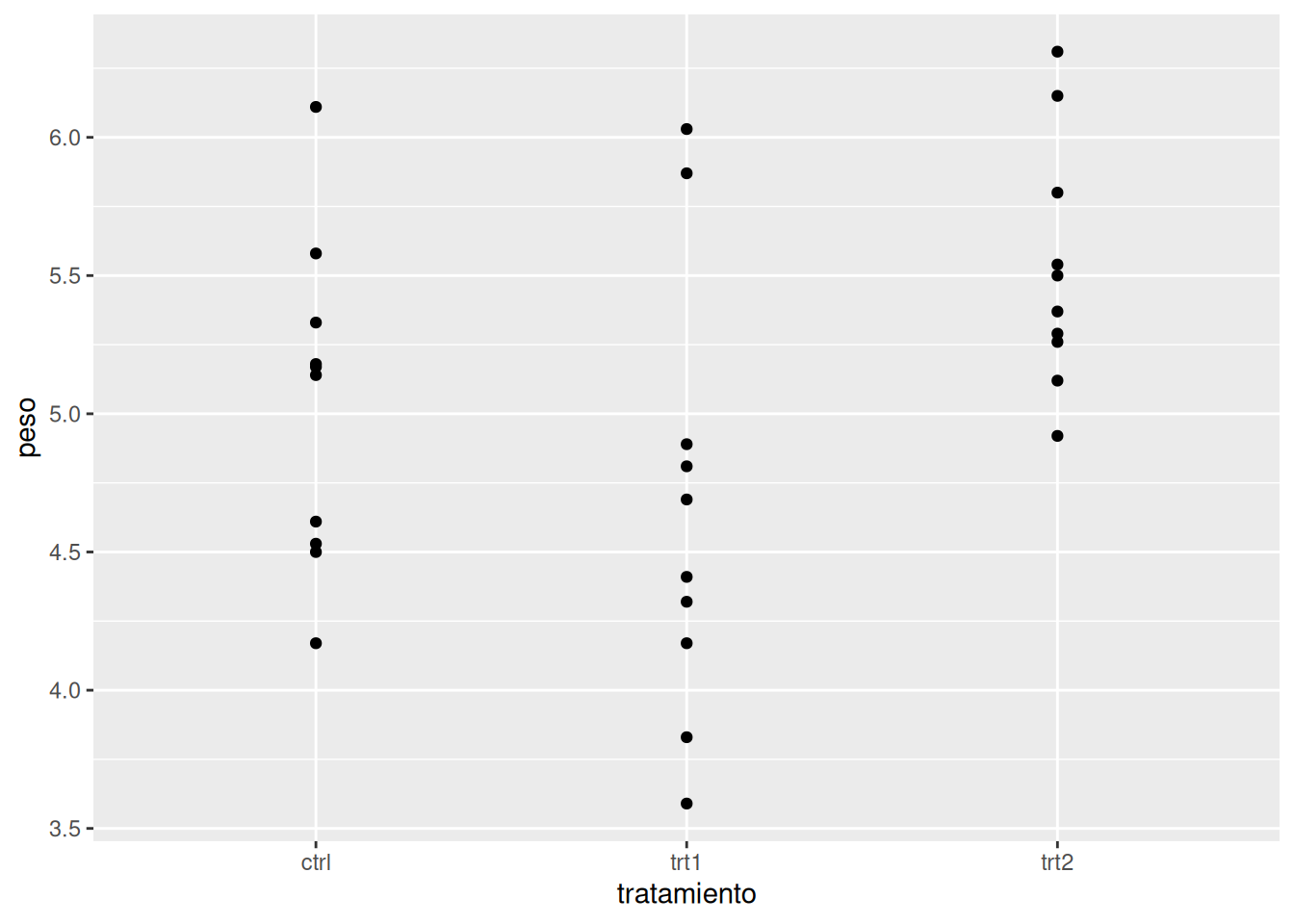
Diagrama de caja y bigotes geom_boxplot()
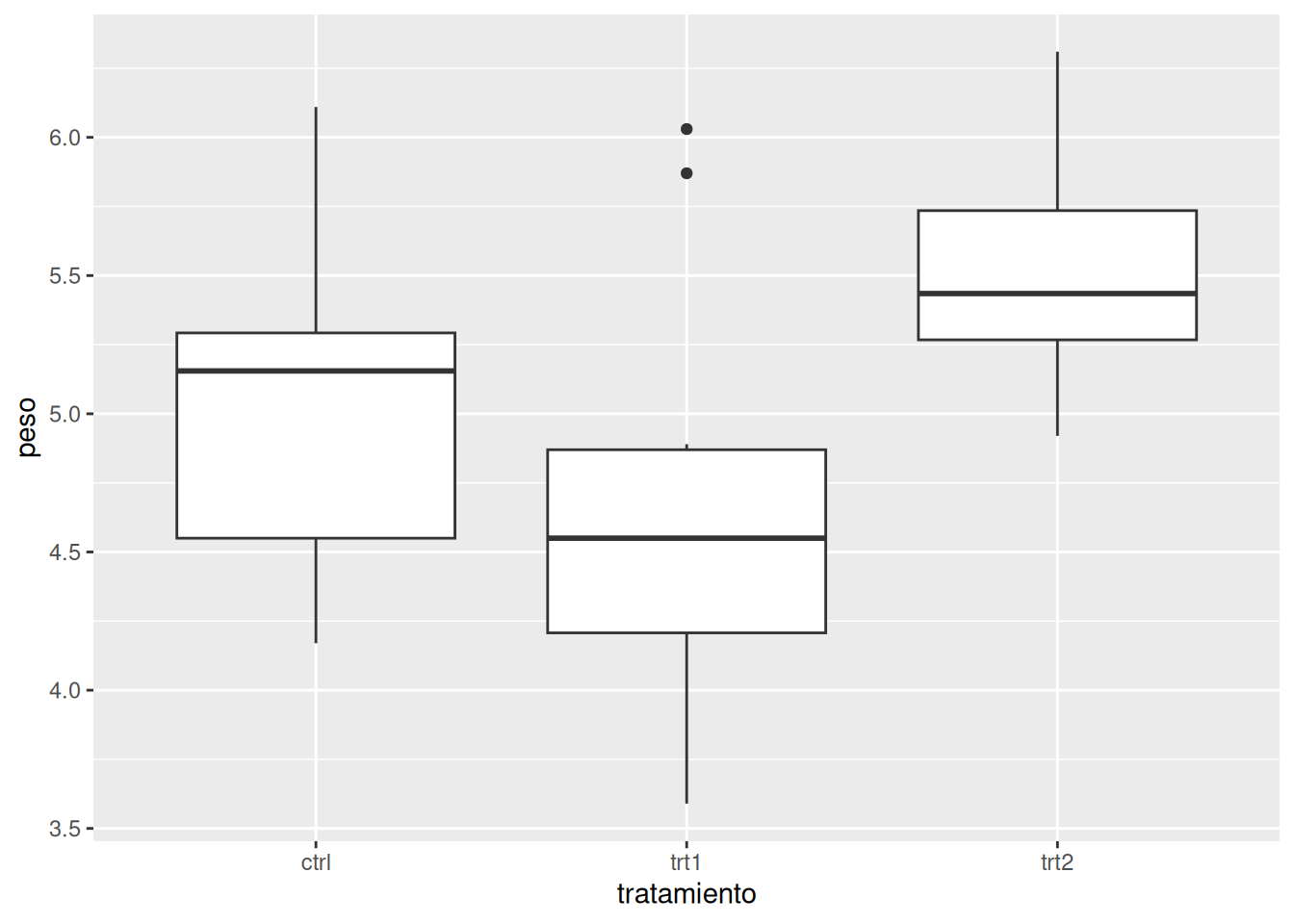
En el capítulo 8 se profundizará en los principales tipos de gráficos y en las opciones de personalización disponibles en ggplot2, con el objetivo de mejorar la calidad y la comunicación visual de los resultados.
7.5 El facetado (facet)
La capa de facetado permite dividir el lienzo principal en múltiples subpaneles, generando un gráfico independiente para cada nivel de una variable categórica. Esta estrategia resulta útil para comparar patrones entre grupos de manera clara y ordenada.
Existen dos funciones principales para facetar: facet_wrap() y facet_grid(). Aunque ambas cumplen un objetivo similar, difieren en la forma en que organizan los paneles.
Es importante destacar que su uso no es obligatorio y dependerá del objetivo del análisis y de las variables disponibles.
7.5.1 facet_wrap()
Se utiliza facet_wrap() cuando se desea facetar el gráfico en función de una sola variable. Los paneles se organizan en filas y columnas de manera automática, adaptándose al espacio disponible. A continuación ejemplificaremos esta función recurriendo al set de datos PlantGrowth_es:
# Divide el gráfico en paneles según el tratamiento
ggplot(data = PlantGrowth_es, aes(x = tratamiento, y = peso)) +
geom_boxplot() +
facet_wrap(~ tratamiento)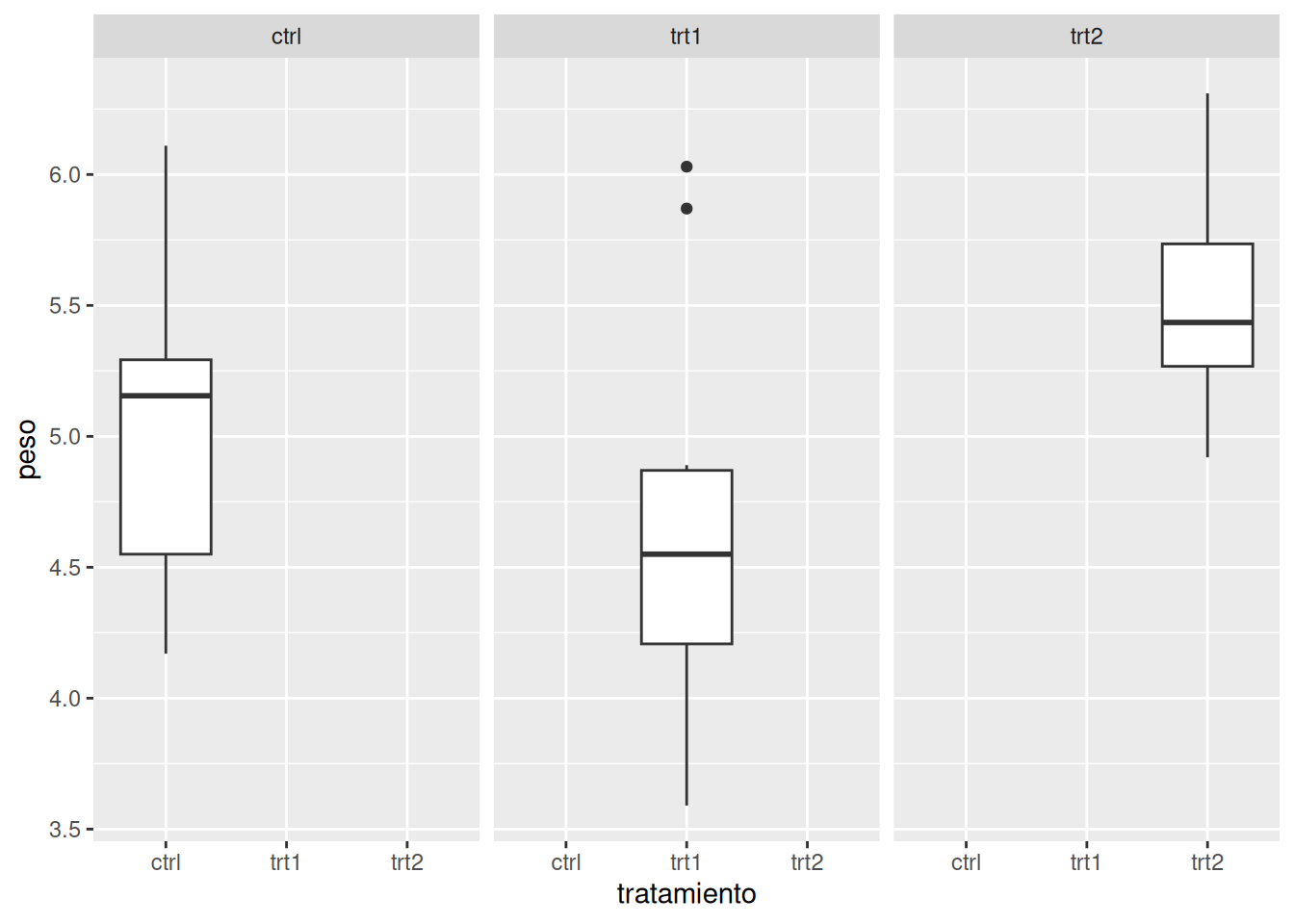
En este caso, se genera un panel para cada nivel de la variable tratamiento.
7.6 facet_grid
La función facet_grid() permite organizar los paneles en una estructura bidimensional (grilla), utilizando dos variables categóricas: una para definir las filas y otra para las columnas.
Para ilustrar su uso, utilizaremos la base de datos MANDARINAS que importamos anteriormente, ya que cuenta con múltiples variables cualitativas. En este caso, cruzaremos la Variedad con el Nivel de daño para observar cómo se distribuye el Peso de los frutos. La relación en facet_grid() se define mediante una fórmula: variable_fila ~ variable_columna.
Antes de realizar la gráfica, utilizaremos la función glimpse() para determinar qué tipo de variable es NIVEL_DE_DAÑO; es decir, si es numérica (double), de texto (character) o factor (factor).
## Rows: 419
## Columns: 8
## $ N <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
## $ GRUPO <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ VARIEDAD <chr> "Clementina", "Clementina", "Clementina", "Clementina", …
## $ N_DE_FRUTO <dbl> 19, 9, 21, 8, 4, 30, 22, 23, 17, 27, 29, 14, 16, 13, 25,…
## $ PESO <dbl> 101, 122, 127, 126, 37, 139, 140, 130, 138, 142, 121, 15…
## $ DIAM_ECUAT <dbl> 64.2, 64.2, 64.7, 64.9, 65.9, 66.4, 67.1, 67.5, 68.2, 68…
## $ NIVEL_DE_DAÑO <dbl> 1, 0, 3, 3, 2, 2, 3, 1, 2, 2, 2, 1, 1, 2, 1, 1, 0, 1, 0,…
## $ COLOR <dbl> 4, 5, 4, 1, 5, 4, 4, 3, 3, 4, 4, 1, 1, 3, 4, 1, 4, 1, 5,…Como se observa, el software R identifica la variable como <dbl> (continua), cuando en realidad debería ser categórica <fct>. Por lo tanto, debemos transformarla antes de elaborar el gráfico.
# Transformamos la variable a factor para que sea reconocida como categoría
MANDARINAS_2 <- MANDARINAS %>%
mutate(NIVEL_DE_DAÑO = as.factor(NIVEL_DE_DAÑO))
# Verificamos nuevamente con glimpse()
glimpse(MANDARINAS_2)## Rows: 419
## Columns: 8
## $ N <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 1…
## $ GRUPO <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
## $ VARIEDAD <chr> "Clementina", "Clementina", "Clementina", "Clementina", …
## $ N_DE_FRUTO <dbl> 19, 9, 21, 8, 4, 30, 22, 23, 17, 27, 29, 14, 16, 13, 25,…
## $ PESO <dbl> 101, 122, 127, 126, 37, 139, 140, 130, 138, 142, 121, 15…
## $ DIAM_ECUAT <dbl> 64.2, 64.2, 64.7, 64.9, 65.9, 66.4, 67.1, 67.5, 68.2, 68…
## $ NIVEL_DE_DAÑO <fct> 1, 0, 3, 3, 2, 2, 3, 1, 2, 2, 2, 1, 1, 2, 1, 1, 0, 1, 0,…
## $ COLOR <dbl> 4, 5, 4, 1, 5, 4, 4, 3, 3, 4, 4, 1, 1, 3, 4, 1, 4, 1, 5,…Ahora la variable NIVEL_DE_DAÑO ya se encuentra como un factor <fct>, contenida junto con las demás variables en un nuevo objeto llamado MANDARINAS_2, se puede avanzar con la representación gráfica de manera correcta:
# Gráfico facetado: Nivel de daño en filas y Variedad en columnas
ggplot(data = MANDARINAS_2, aes(x = VARIEDAD, y = PESO, fill = NIVEL_DE_DAÑO)) +
geom_boxplot() +
facet_grid(NIVEL_DE_DAÑO ~ VARIEDAD) +
theme_bw() +
labs(title = "Distribución de peso por variedad y nivel de daño",
x = "Variedad",
y = "Peso (g)",
fill = "Nivel de daño")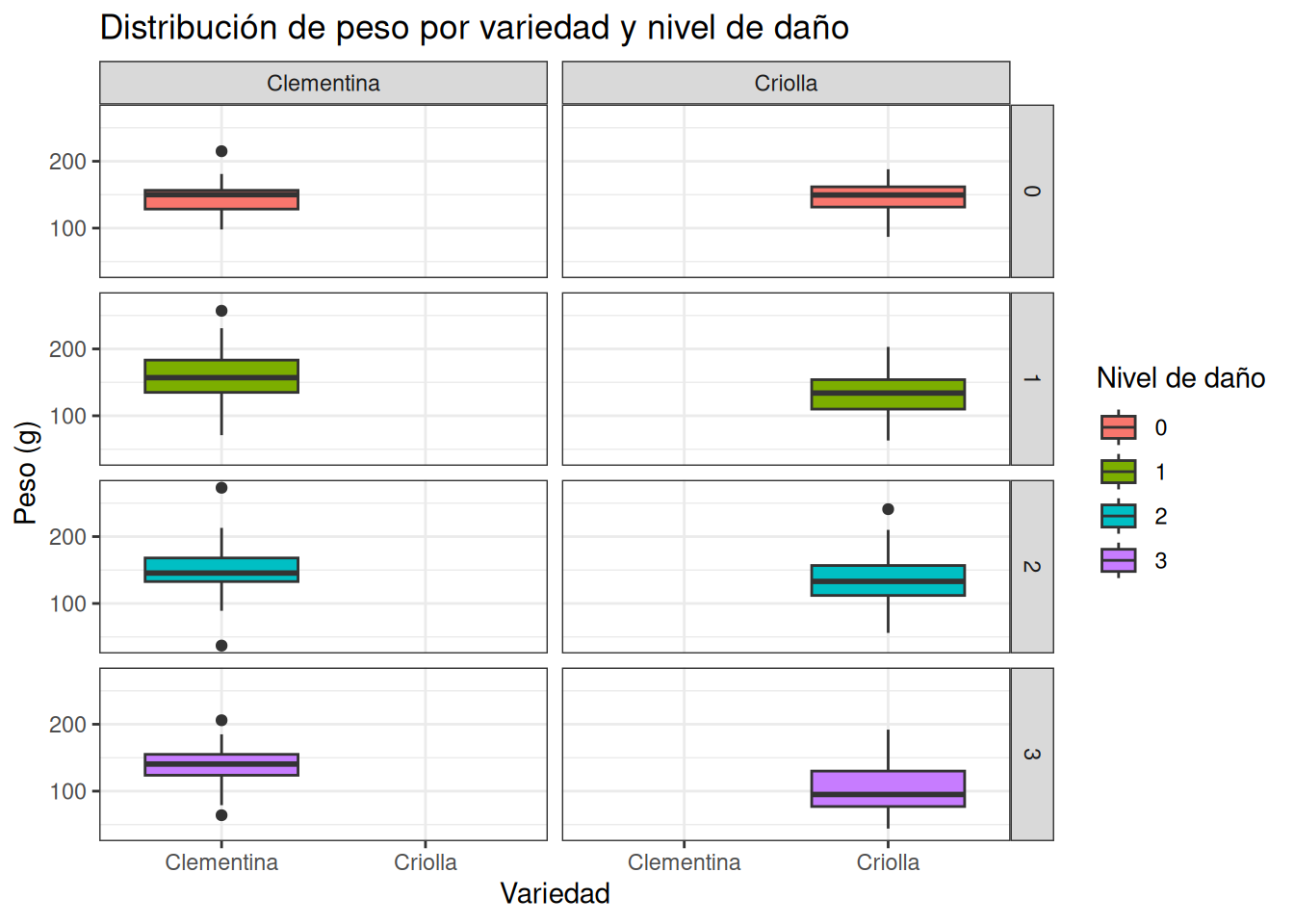
En este gráfico resultante, podemos comparar de forma directa el peso de las mandarinas “Criollas” vs. “Clementinas” segmentadas por su estado sanitario. Nótese cómo, por defecto, todos los paneles comparten la misma escala en los ejes, lo que facilita una comparación visual entre grupos.
7.7 Los temas (themes)
Un tema es un conjunto predefinido de parámetros que controlan exclusivamente la apariencia visual del gráfico. Afecta elementos como el fondo, el estilo de los ejes, las líneas de la cuadrícula, los márgenes y las tipografías, pero no altera en absoluto la forma en que las geometrías (geoms) presentan los datos.
Aunque el estilo predeterminado de ggplot2 es theme_gray(), existen múltiples alternativas integradas para lograr el aspecto deseado. Algunos de los temas más utilizados son:
theme_gray(): El tema por defecto, con fondo gris y líneas de cuadrícula blancas.theme_bw(): Fondo blanco con bordes negros y cuadrícula gris.theme_classic(): Fondo blanco limpio sin cuadrícula, con ejes X e Y remarcados (muy utilizado en publicaciones científicas tradicionales).theme_minimal(): Diseño minimalista sin marcos ni fondo, manteniendo solo líneas de cuadrícula sutiles para no distraer.theme_dark(): Fondo oscuro, ideal para generar contraste con colores brillantes o destacar datos específicos.
A continuación, se presentan algunos ejemplos de aplicación:
# Tema oscuro
ggplot(PlantGrowth_es, aes(x = tratamiento, y = peso)) +
geom_boxplot() +
theme_dark()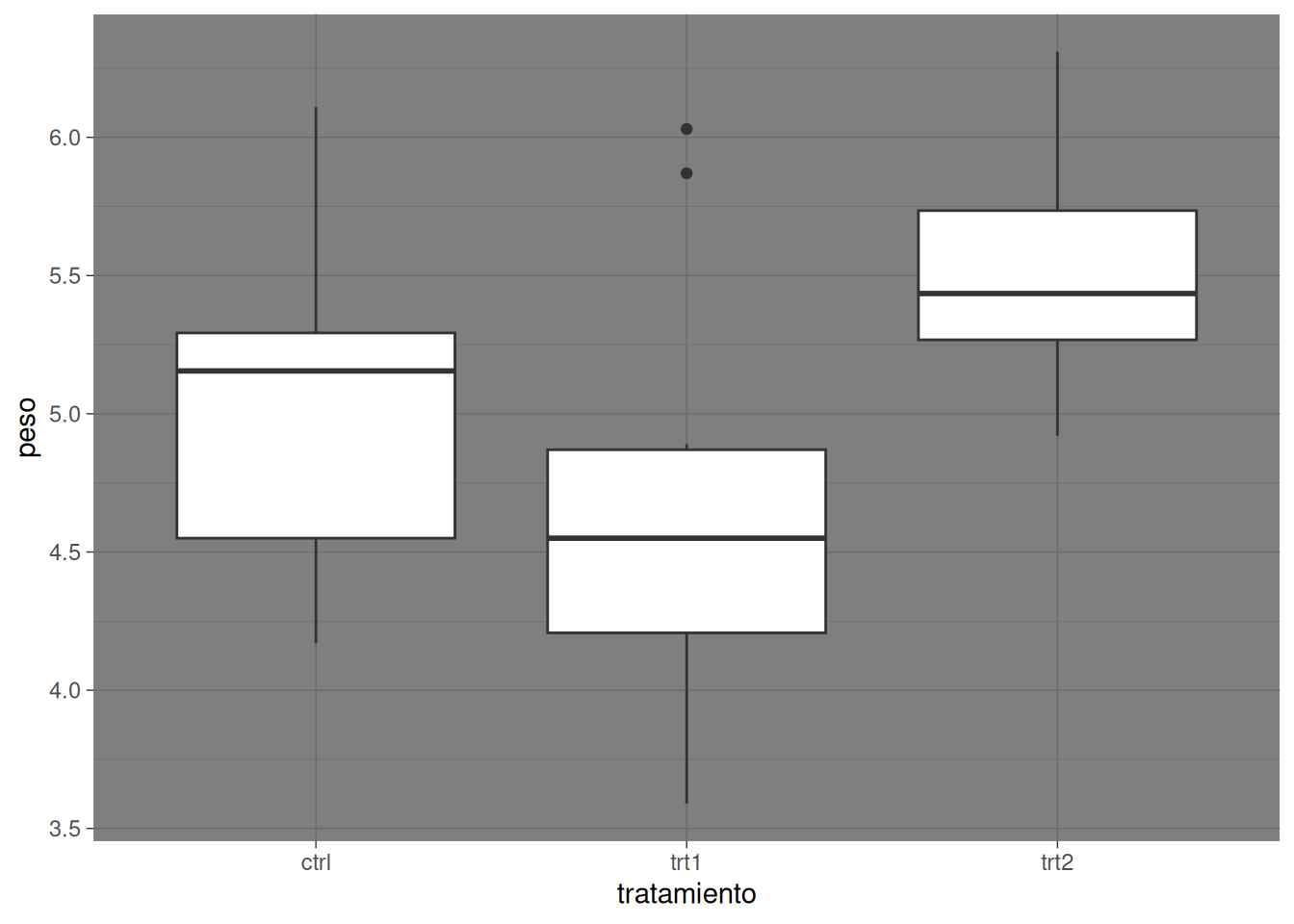
# Tema clásico
ggplot(PlantGrowth_es, aes(x = tratamiento, y = peso)) +
geom_boxplot() +
theme_classic()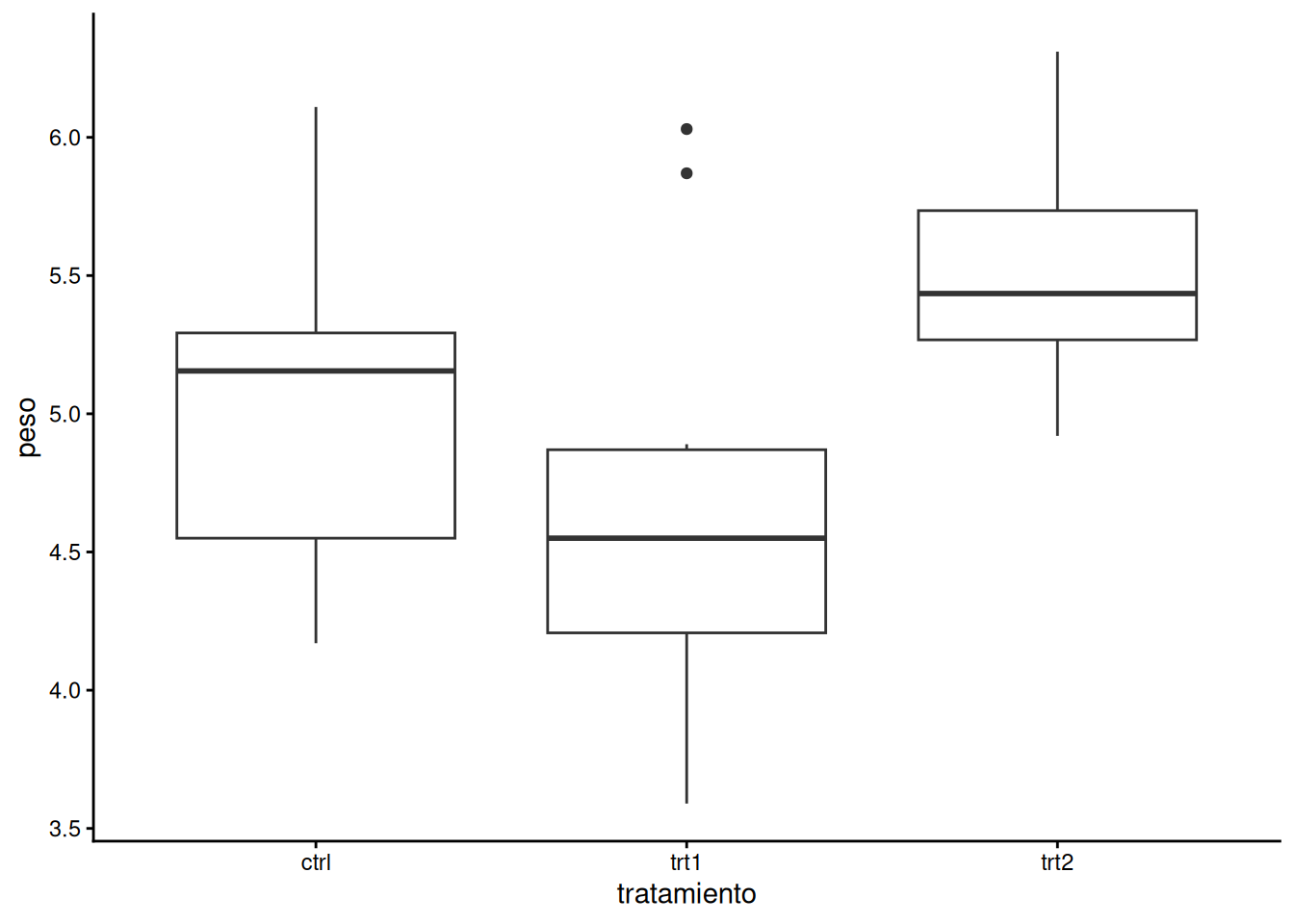
# Tema minimalista
ggplot(PlantGrowth_es, aes(x = tratamiento, y = peso)) +
geom_boxplot() +
theme_minimal()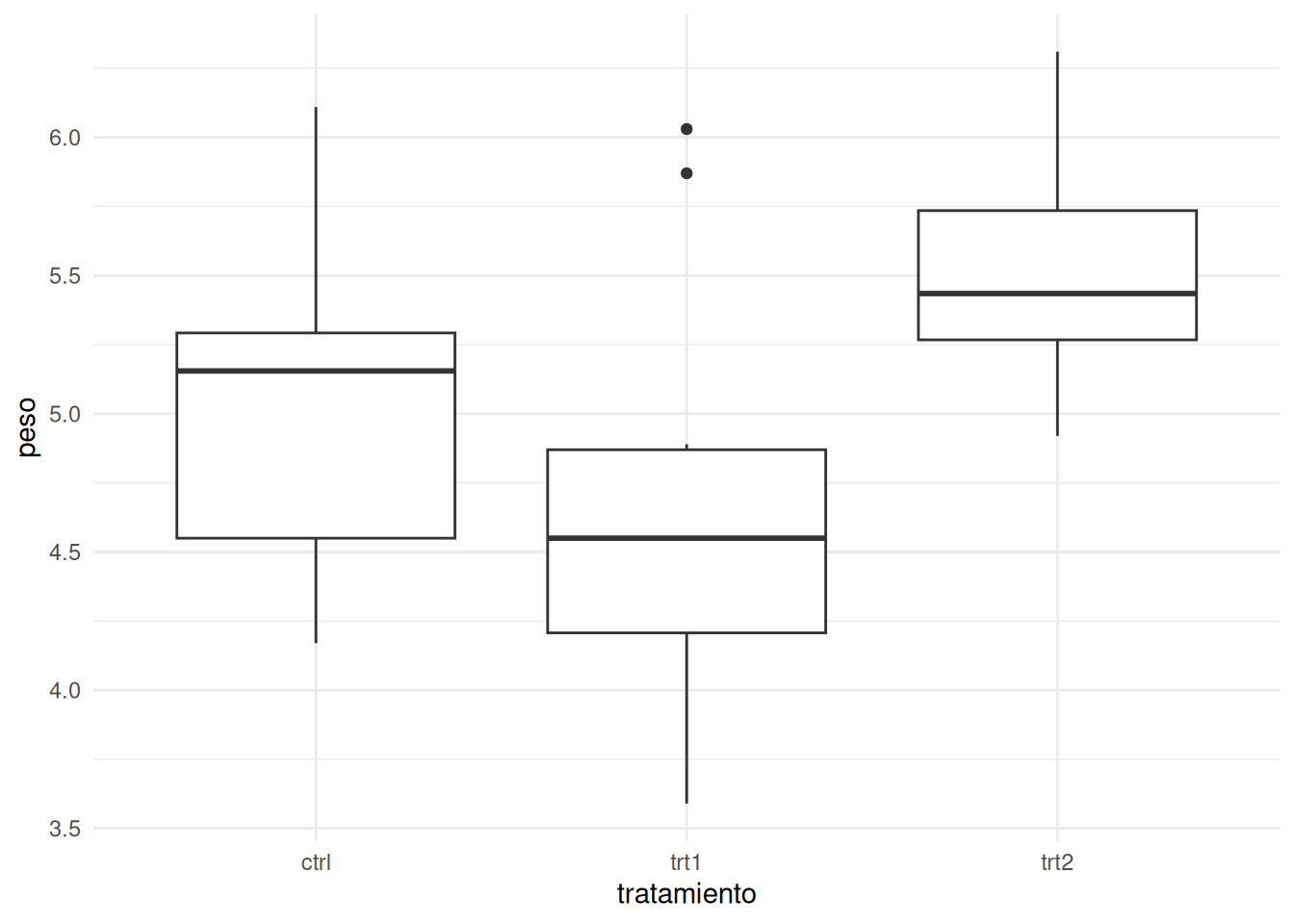
7.8 Integración de capas
Una de las principales ventajas de ggplot2 es la posibilidad de combinar múltiples capas en un mismo gráfico. A través del operador de suma (+), es posible construir visualizaciones complejas agregando de manera secuencial geometrías, facetas, escalas y configuraciones estéticas.
El siguiente ejemplo ilustra la construcción de un gráfico completo que superpone un diagrama de cajas con los datos individuales en puntos, segmentado por facetas y con una presentación visual pulida.
Para asegurar que la visualización sea comprensible y comunique su mensaje de manera efectiva, incorporamos una capa fundamental: labs() (labels o etiquetas) que permite personalizar los textos informativos del gráfico. En nuestro ejemplo utilizaremos:
title: para definir el título principal del gráfico.x: para indicar el nombre o unidad de medida del eje horizontal.y: para indicar el nombre o unidad de medida del eje vertical.
A continuación se presenta un ejemplo de integración de capas en un mismo gráfico:
# Construcción del gráfico
ggplot(PlantGrowth_es, aes(x = tratamiento, y = peso, fill = tratamiento)) + # fill asigna un color distinto a cada caja
geom_boxplot() + # Agrega la geometría de cajas
theme_classic() + # Aplica un tema de fondo
labs(title = "Comparación de peso seco (g) por tratamiento", # Título principal
x = "Tratamiento", # Etiqueta del eje X
y = "Peso seco (g)", # Etiqueta del eje Y
fill = "Tratamiento") # Título de la leyenda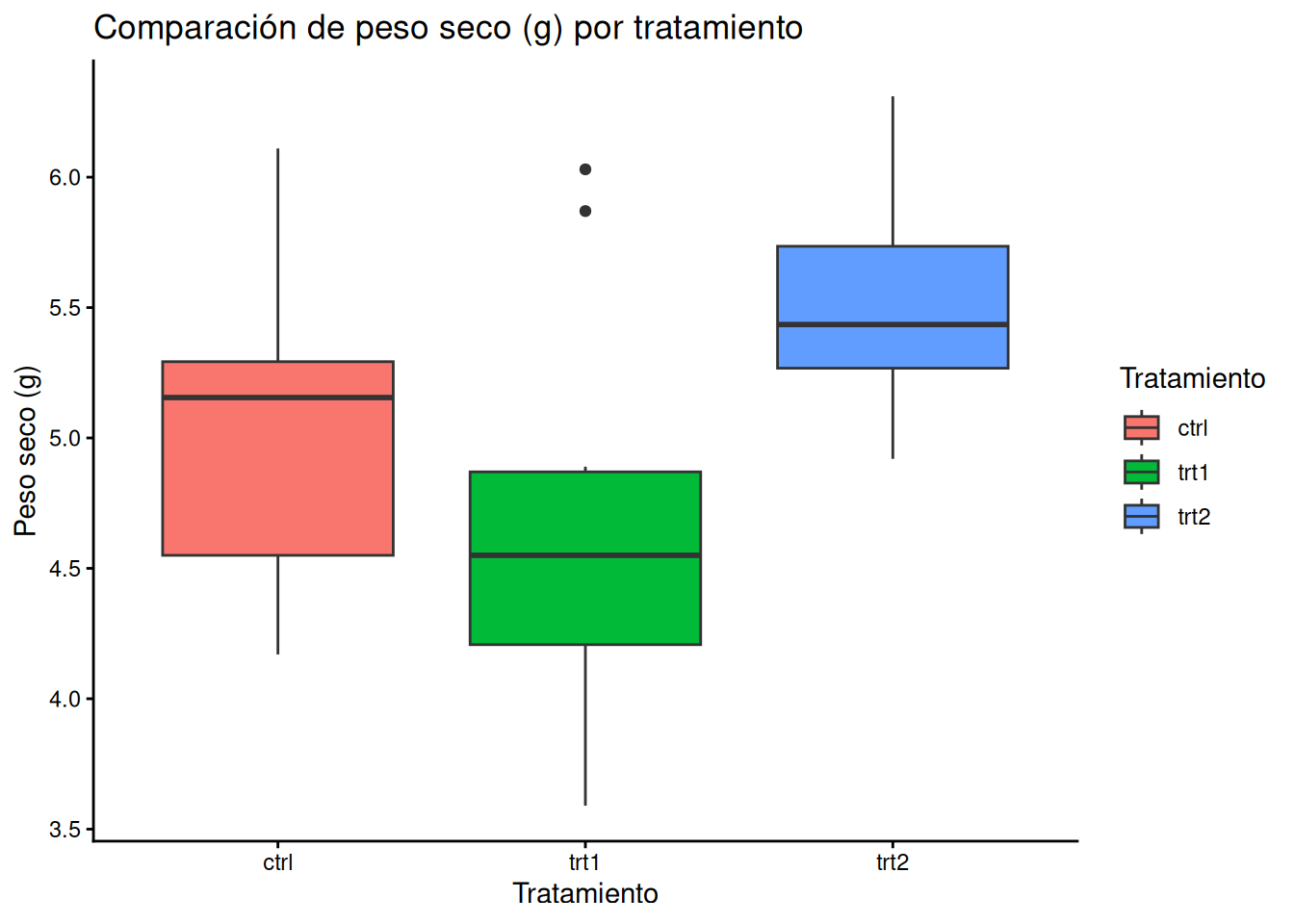
La visualización de datos no solo permite comprenderlos en profundidad, sino que además constituye un paso fundamental para avanzar hacia análisis más complejos y una comunicación efectiva de la información.